
Shangbin Feng
PhD student at University of Washington, working with Yulia Tsvetkov. Model collaboration, social NLP, networks and structures.
Links: CV Email Twitter Github Google Scholar
Shangbin Feng
PhD student at University of Washington, working with Yulia Tsvetkov. Model collaboration, social NLP, networks and structures.
Links: CV Email Twitter Github Google Scholar
Publications
Filter: Highlight 🔎 Lead/co-Lead ✍️ All Papers 📖
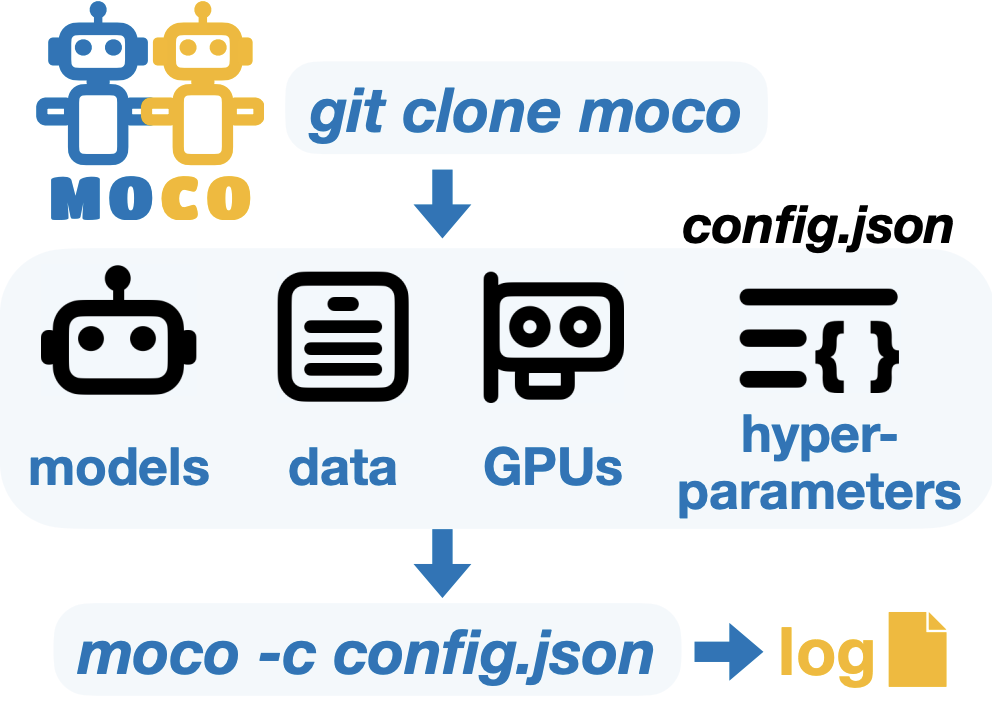
MoCo: A One-Stop Shop for Model Collaboration Research
Shangbin Feng=, Yuyang Bai=, Ziyuan Yang=, Yike Wang, Zhaoxuan Tan, Jiajie Yan, Zhenyu Lei, Wenxuan Ding, Weijia Shi, Haojin Wang, Zhenting Qi, Yuru Jiang, Heng Wang, Chengsong Huang, Yu Fei, Jihan Yao, Yilun Du, Luke Zettlemoyer, Yejin Choi, Yulia Tsvetkov
Moco, a one-stop shop to run, evaluate, compare 26+ model collaboration algorithms across diverse tasks and settings. Please contribute your model collaboration algorithms!
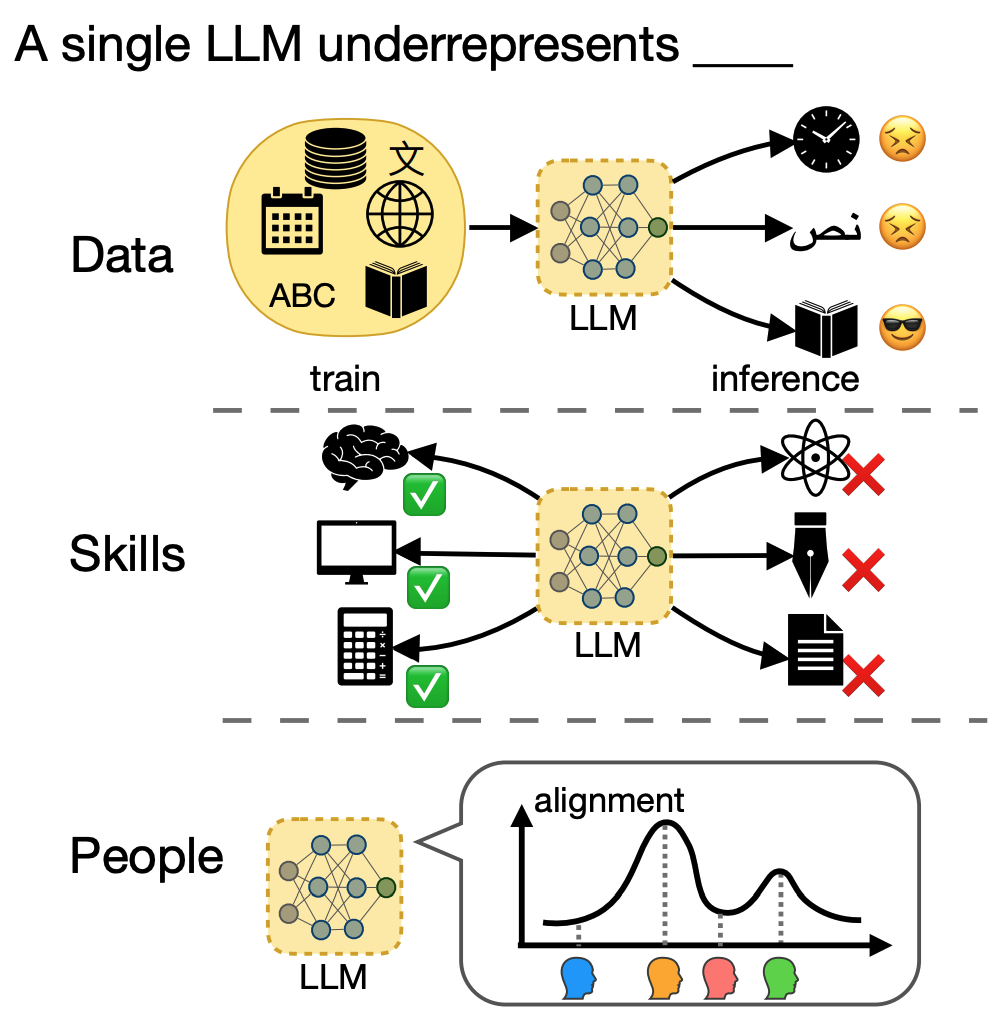
When One LLM Drools, Multi-LLM Collaboration Rules
Shangbin Feng, Wenxuan Ding, Alisa Liu, Zifeng Wang, Weijia Shi, Yike Wang, Shannon Zejiang Shen, Xiaochuang Han, Hunter Lang, Chen-Yu Lee, Tomas Pfister, Yejin Choi, Yulia Tsvetkov
ACL 2026 paper
One LLM underrepresents the extensive diversity of data, skills, and people, thus we need multi-LLM collaboration for collaborative development and compositional intelligence.
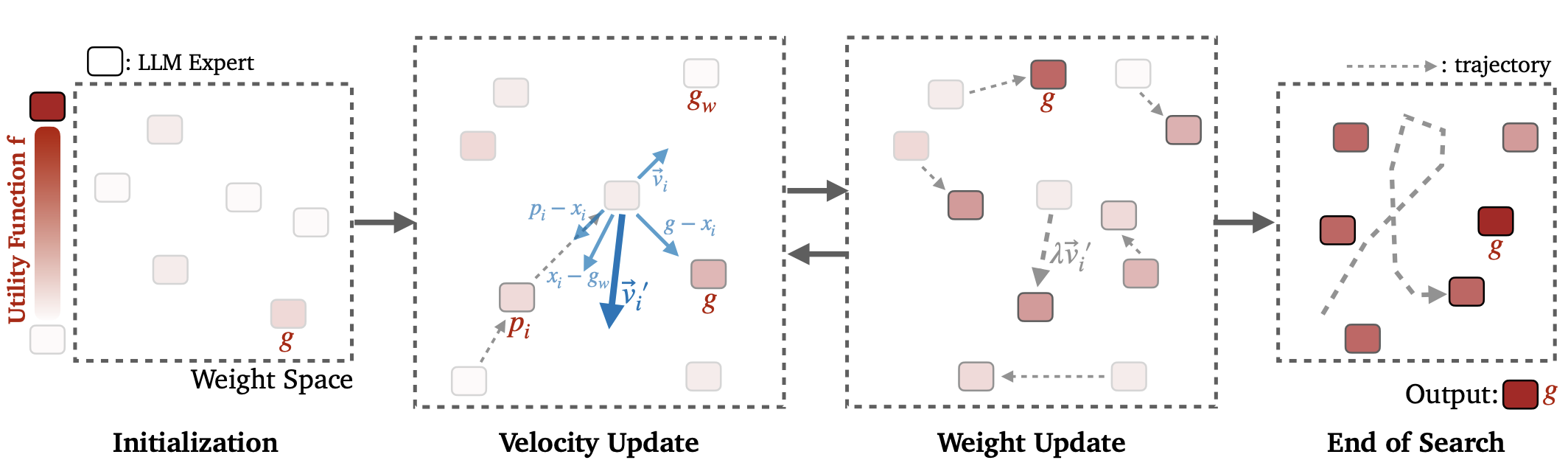
Model Swarms: Collaborative Search to Adapt LLM Experts via Swarm Intelligence
Shangbin Feng, Zifeng Wang, Yike Wang, Sayna Ebrahimi, Hamid Palangi, Lesly Miculicich, Achin Kulshrestha, Nathalie Rauschmayr, Yejin Choi, Yulia Tsvetkov, Chen-Yu Lee, Tomas Pfister
Multiple LLM experts collaboratively search in the weight space for adaptation via swarm intelligence.
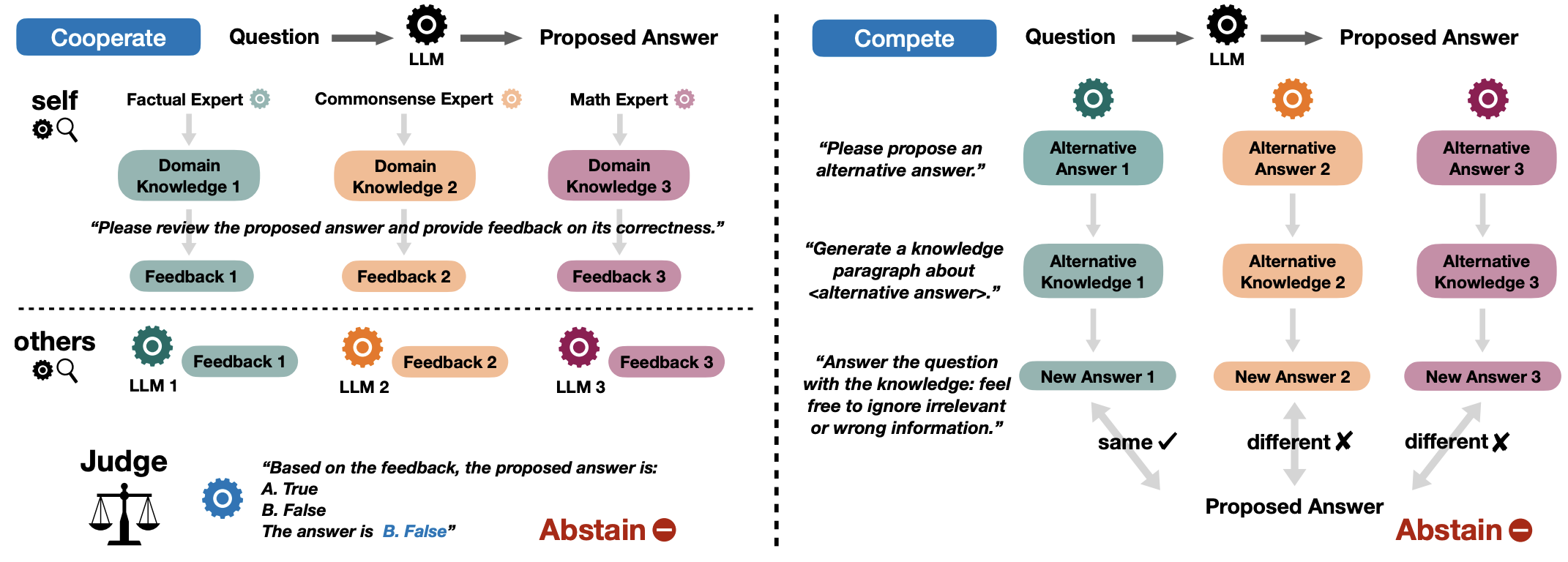
Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration
Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov
ACL 2024 🏆 Area Chair Award, QA Track 🏆 Outstanding Paper Award paper code
We benchmark LLM abstention with calibration-, training-, prompting-, and consistency-based approaches. Informed by their weaknesses, we propose collaboration-based approaches, where multiple LLMs work in cooperation or competition to identify the knowledge gaps in each other and produce abstain decisions.
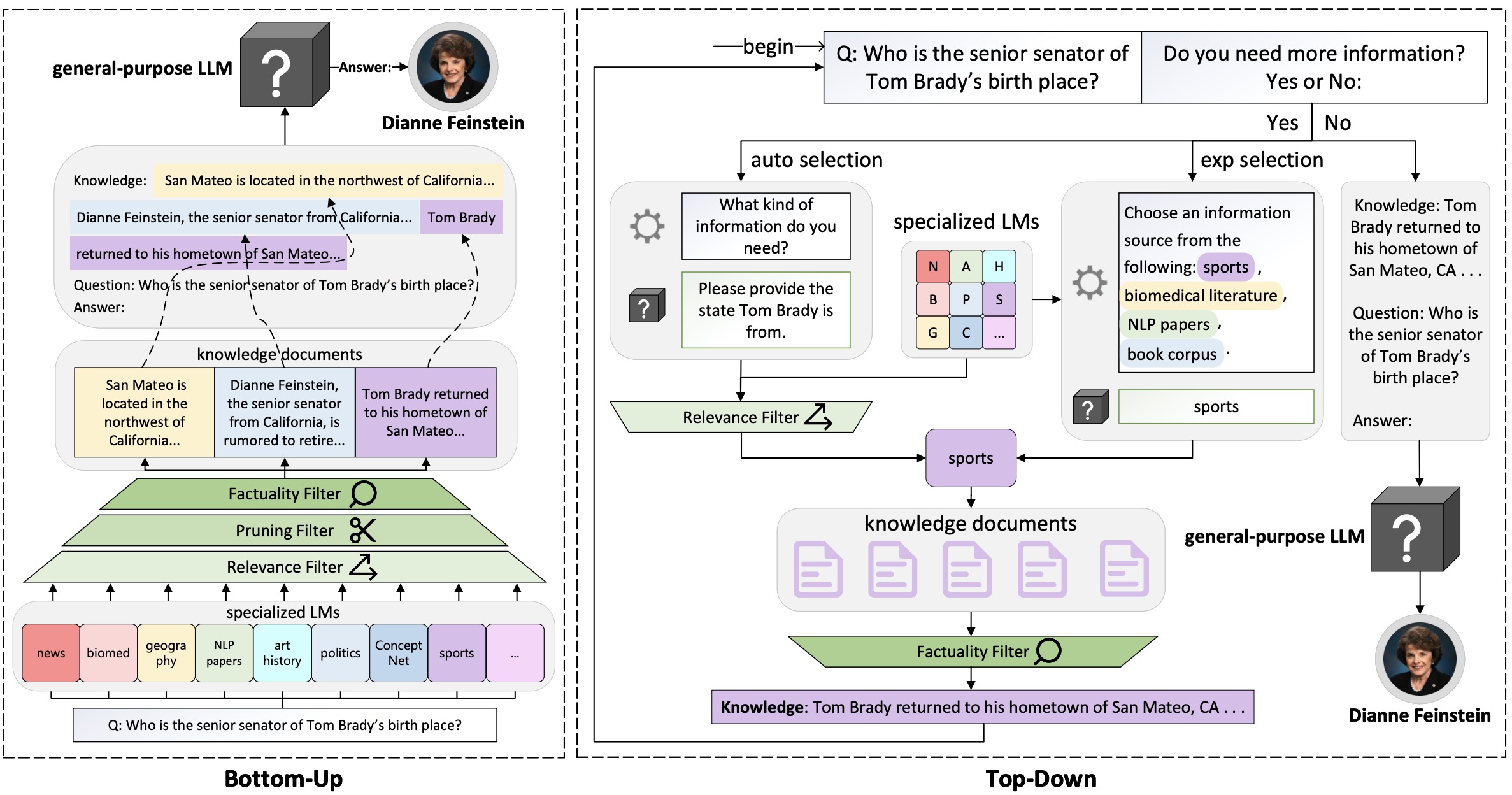
Knowledge Card: Filling LLMs' Knowledge Gaps with Plug-in Specialized Language Models
Shangbin Feng, Weijia Shi, Yuyang Bai, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov
We propose Knowledge Card, a community-driven initiative to empower black-box LLMs with modular and collaborative knowledge. By incorporating the outputs of independently trained, small, and specialized LMs, we make LLMs better knowledge models by empowering them with temporal knowledge update, multi-domain knowledge synthesis, and continued improvement through collective efforts.
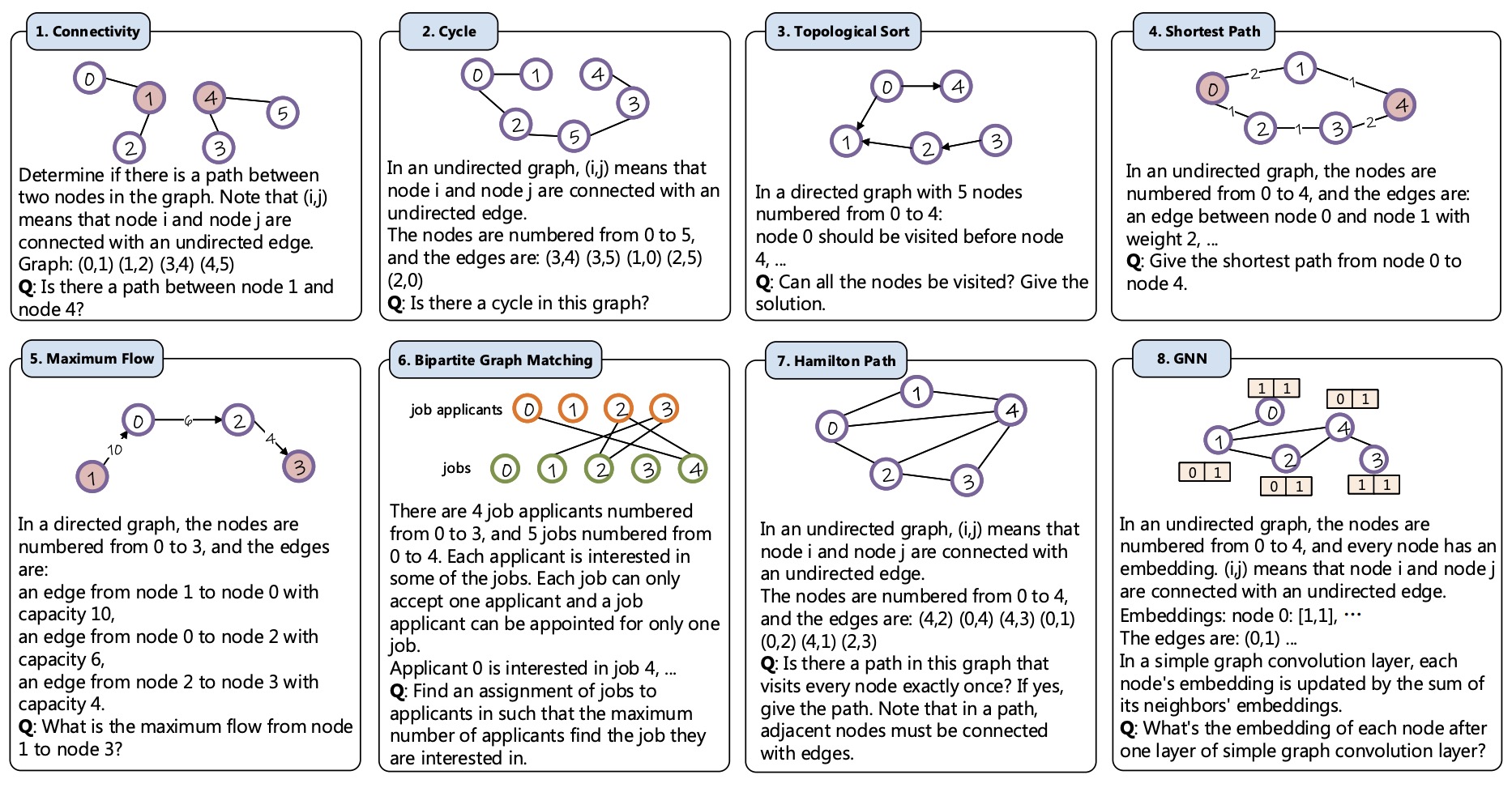
Can Language Models Solve Graph Problems in Natural Language?
Heng Wang=, Shangbin Feng=, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, Yulia Tsvetkov
NeurIPS 2023, spotlight paper code
Are language models graph reasoners? We propose the NLGraph benchmark, a test bed for graph-based reasoning designed for language models in natural language. We find that LLMs are preliminary graph thinkers while the most advanced graph reasoning tasks remain an open research question.
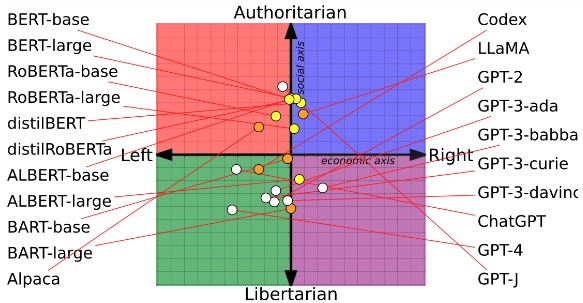
From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models
Shangbin Feng, Chan Young Park, Yuhan Liu, Yulia Tsvetkov
ACL 2023 🏆 Best Paper Award paper code Washington Post MIT Tech Review Montreal AI Ethics Institute Better Conflict Bulletin
We propose to study the political bias propagation pipeline from pretraining data to language models to downstream tasks. We find that language models do have political biases, such biases are in part picked up from pretraining corpora, and they could result in fairness issues in LM-based solutions to downstream tasks.
Miscellaneous