
Shangbin Feng
PhD student at University of Washington, working with Yulia Tsvetkov. Model collaboration, social NLP, networks and structures.
Links: CV Email Twitter Github Google Scholar
Shangbin Feng
PhD student at University of Washington, working with Yulia Tsvetkov. Model collaboration, social NLP, networks and structures.
Links: CV Email Twitter Github Google Scholar
Publications
Filter: Highlight 🔎 Lead/co-Lead ✍️ All Papers 📖
2026
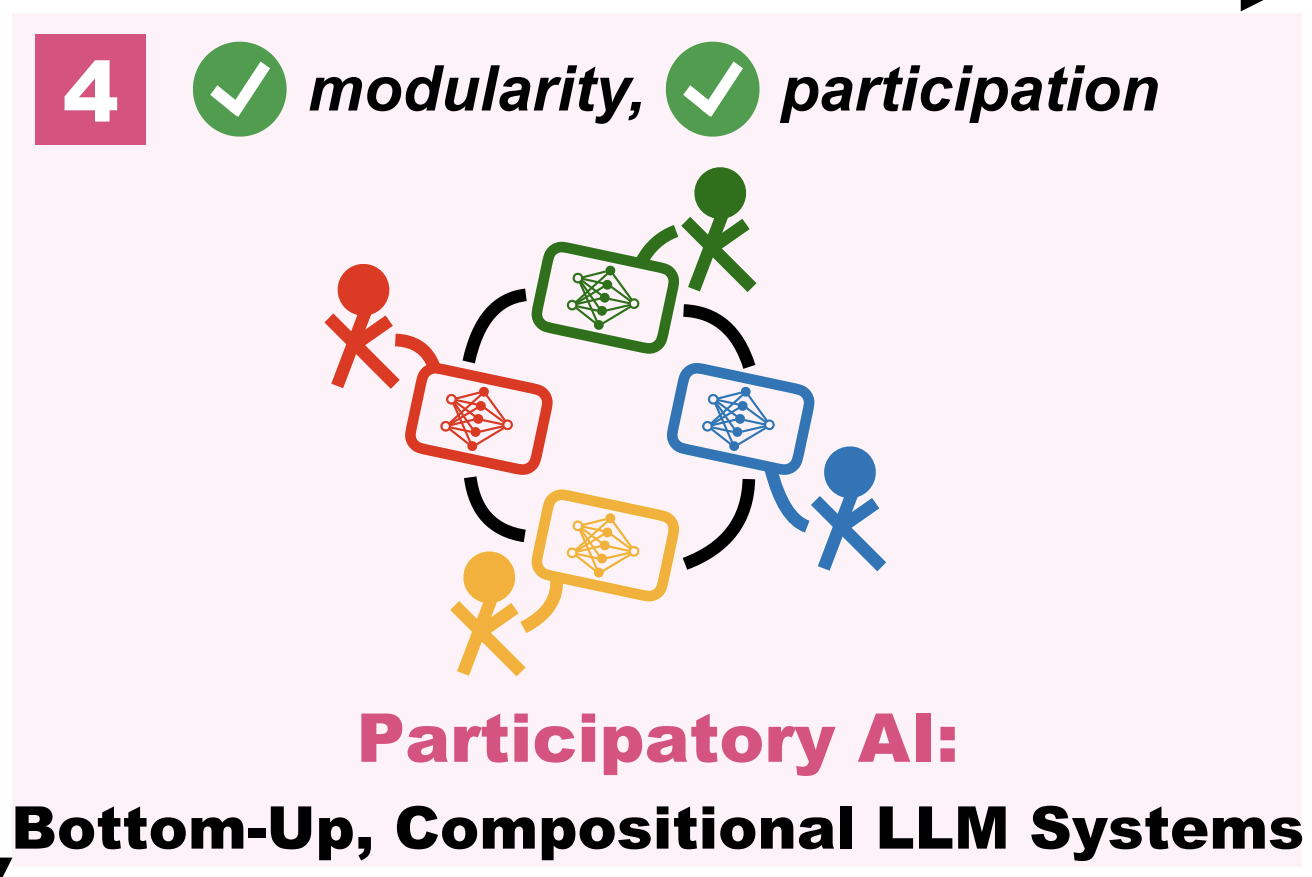
Scaling Participation in Modular AI Systems
Shangbin Feng, Yike Wang, Weijia Shi, Luke Zettlemoyer, Yejin Choi, Yulia Tsvetkov
arxiv paper
Scaling participation in building bottom-up, modular AI systems.
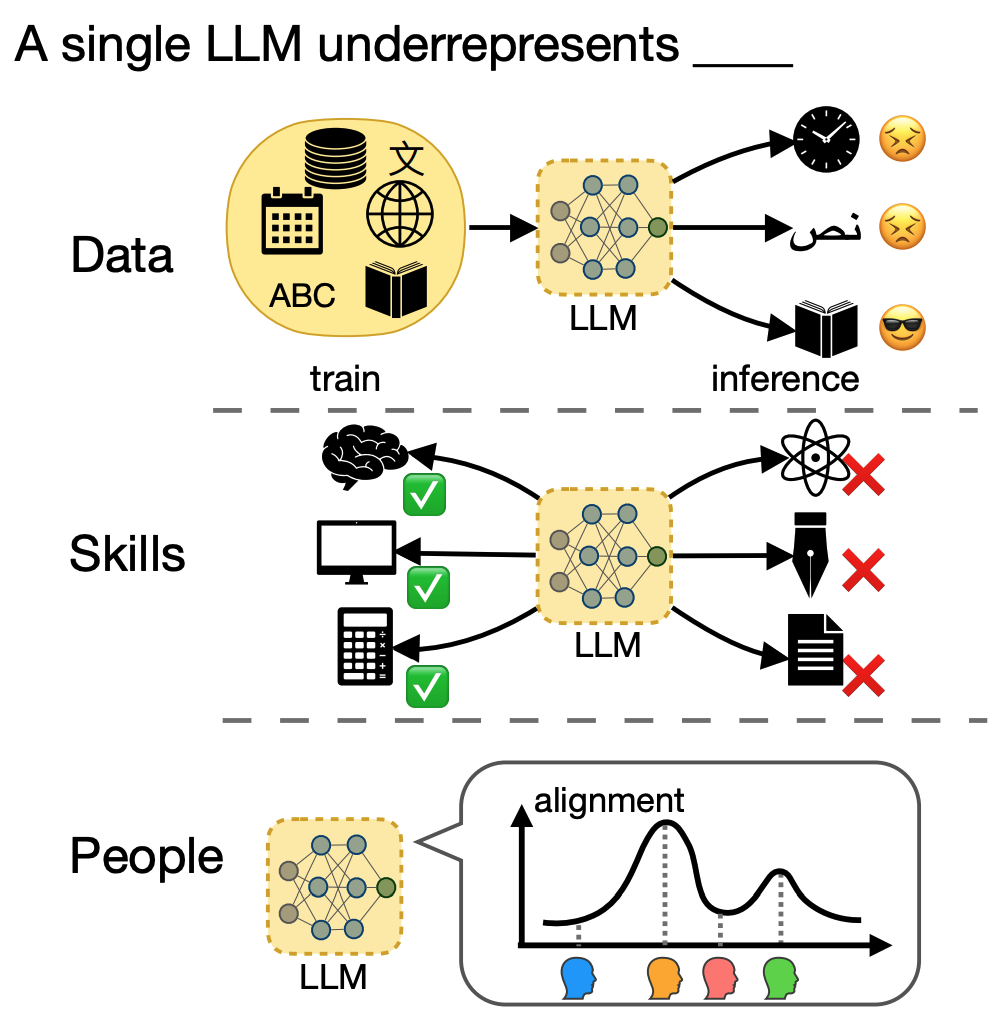
When One LLM Drools, Multi-LLM Collaboration Rules
Shangbin Feng, Wenxuan Ding, Alisa Liu, Zifeng Wang, Weijia Shi, Yike Wang, Shannon Zejiang Shen, Xiaochuang Han, Hunter Lang, Chen-Yu Lee, Tomas Pfister, Yejin Choi, Yulia Tsvetkov
ACL 2026 paper
One LLM underrepresents the extensive diversity of data, skills, and people, thus we need multi-LLM collaboration for collaborative development and compositional intelligence.
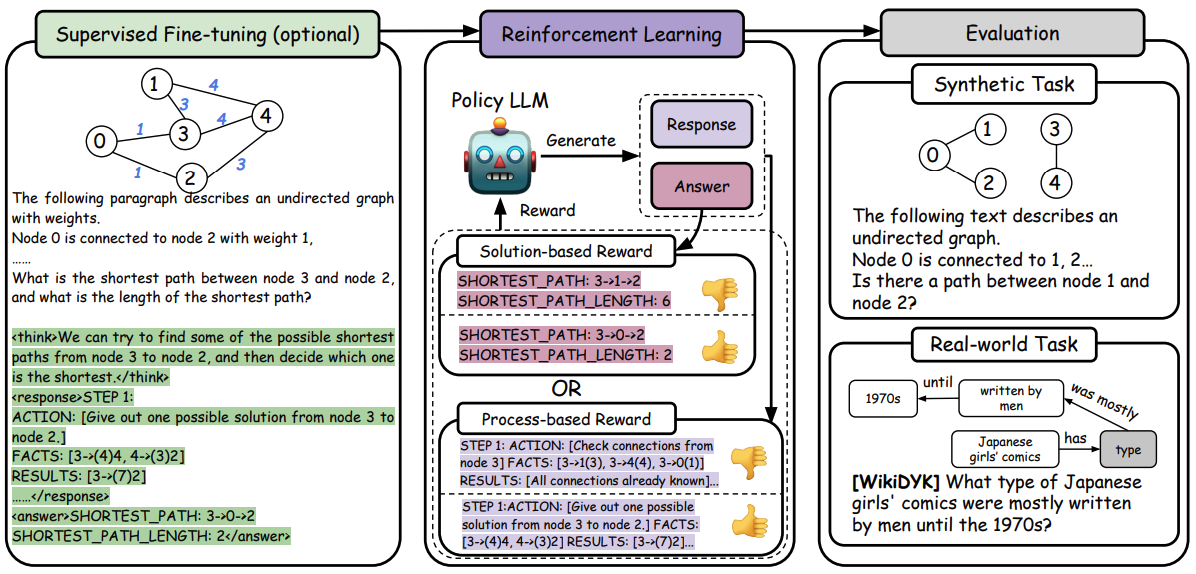
Generalizable LLM Learning of Graph Synthetic Data with Reinforcement Learning
Yizhuo Zhang=, Heng Wang=, Shangbin Feng=, Zhaoxuan Tan, Xinyun Liu, Yulia Tsvetkov
ACL 2026, findings paper
RL to make graph synthetic data finally useful/meaningful for real-world LLM tasks with graph implications.
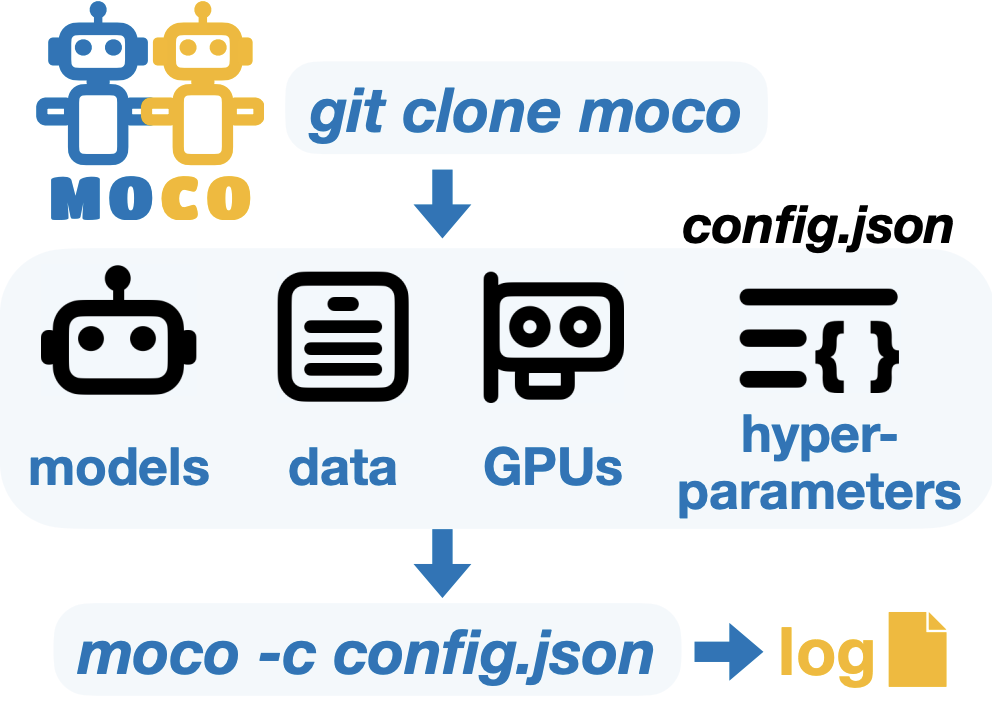
MoCo: A One-Stop Shop for Model Collaboration Research
Shangbin Feng=, Yuyang Bai=, Ziyuan Yang=, Yike Wang, Zhaoxuan Tan, Jiajie Yan, Zhenyu Lei, Wenxuan Ding, Weijia Shi, Haojin Wang, Zhenting Qi, Yuru Jiang, Heng Wang, Chengsong Huang, Yu Fei, Jihan Yao, Yilun Du, Luke Zettlemoyer, Yejin Choi, Yulia Tsvetkov
Moco, a one-stop shop to run, evaluate, compare 26+ model collaboration algorithms across diverse tasks and settings. Please contribute your model collaboration algorithms!
2025
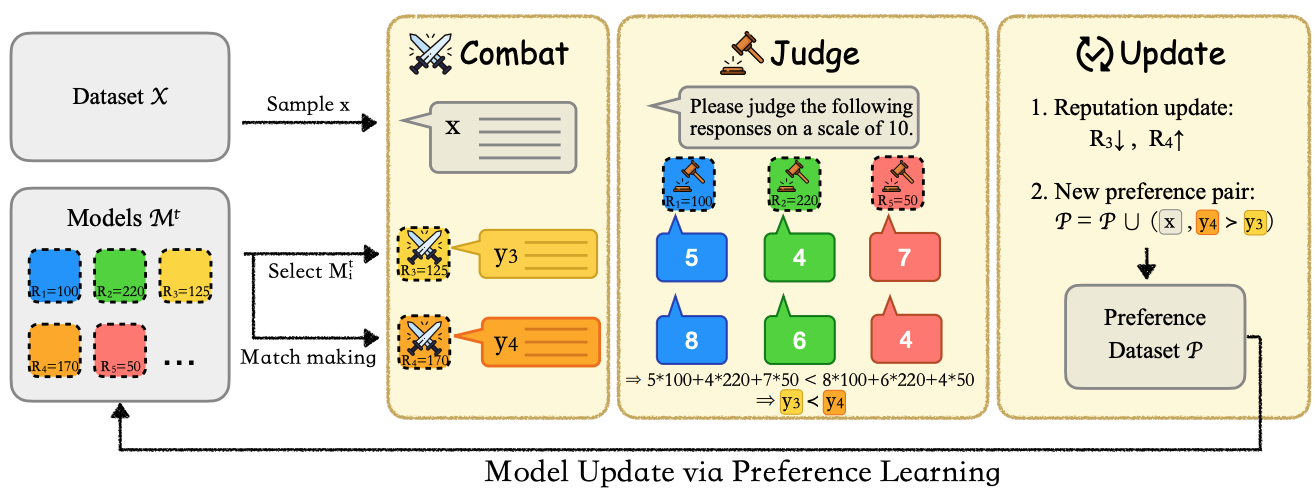
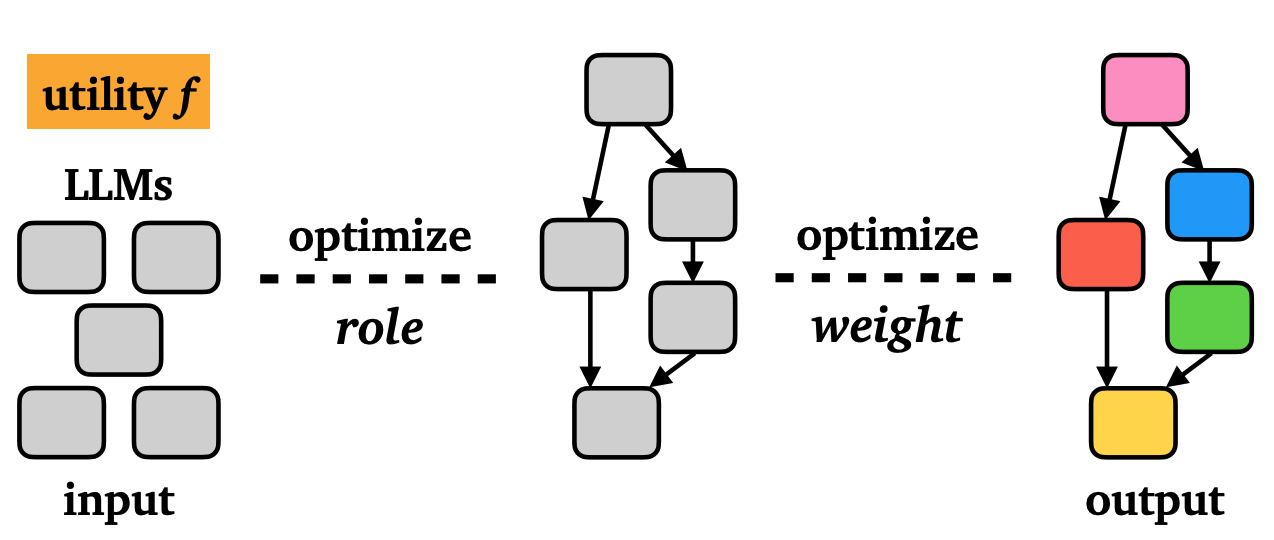
Heterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-LLM Systems
Shangbin Feng, Zifeng Wang, Palash Goyal, Yike Wang, Weijia Shi, Huang Xia, Hamid Palangi, Luke Zettlemoyer, Yulia Tsvetkov, Chen-Yu Lee, Tomas Pfister
We jointly optimize the graph structure and model weights of multi-LLM systems through swarm intelligence.
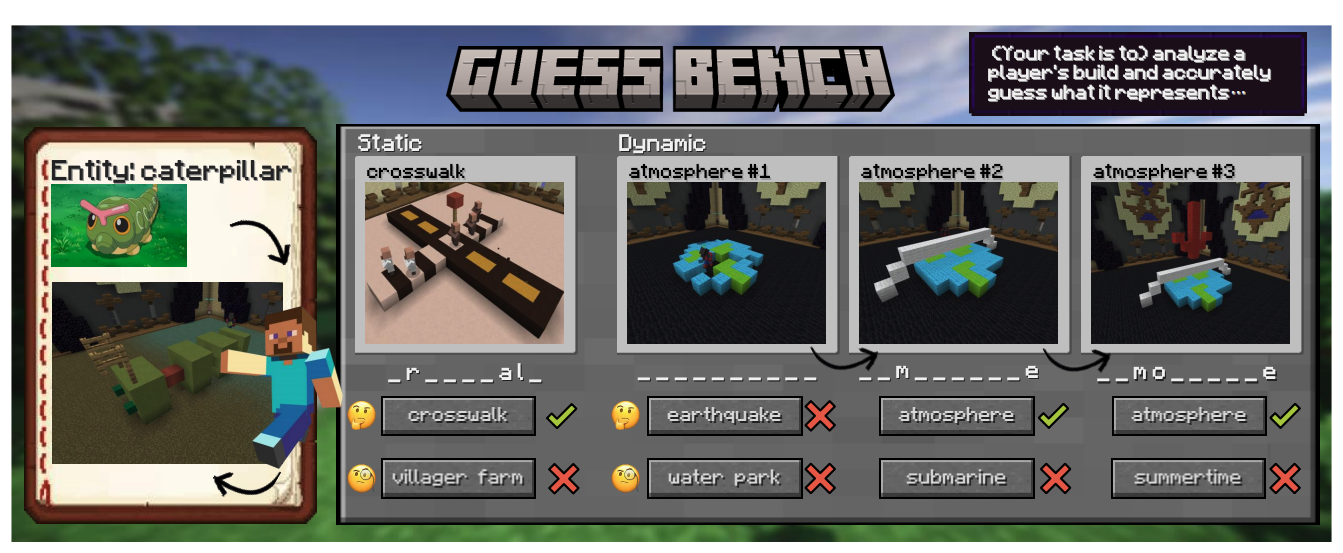
GuessBench: Sensemaking Multimodal Creativity in the Wild
Zifeng Zhu=, Shangbin Feng=, Herun Wan, Ningnan Wang, Minnan Luo, Yulia Tsvetkov
arxiv paper
VLMs make sense of creativity in the wild - guessing the entity/concept behind player builds in actual Minecraft gameplay.
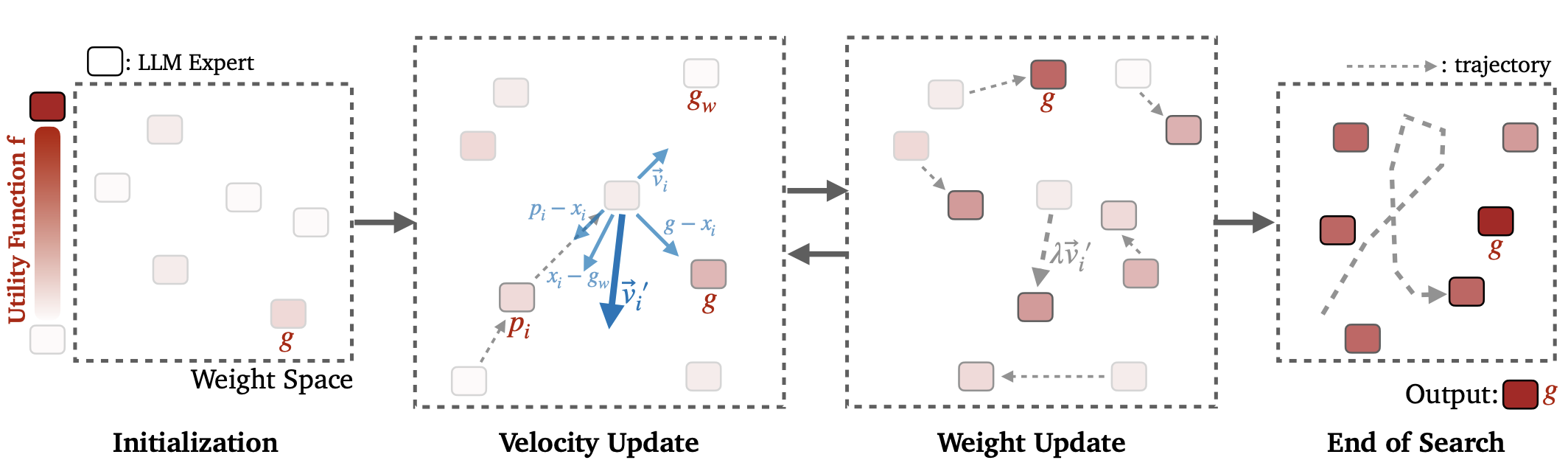
Model Swarms: Collaborative Search to Adapt LLM Experts via Swarm Intelligence
Shangbin Feng, Zifeng Wang, Yike Wang, Sayna Ebrahimi, Hamid Palangi, Lesly Miculicich, Achin Kulshrestha, Nathalie Rauschmayr, Yejin Choi, Yulia Tsvetkov, Chen-Yu Lee, Tomas Pfister
Multiple LLM experts collaboratively search in the weight space for adaptation via swarm intelligence.
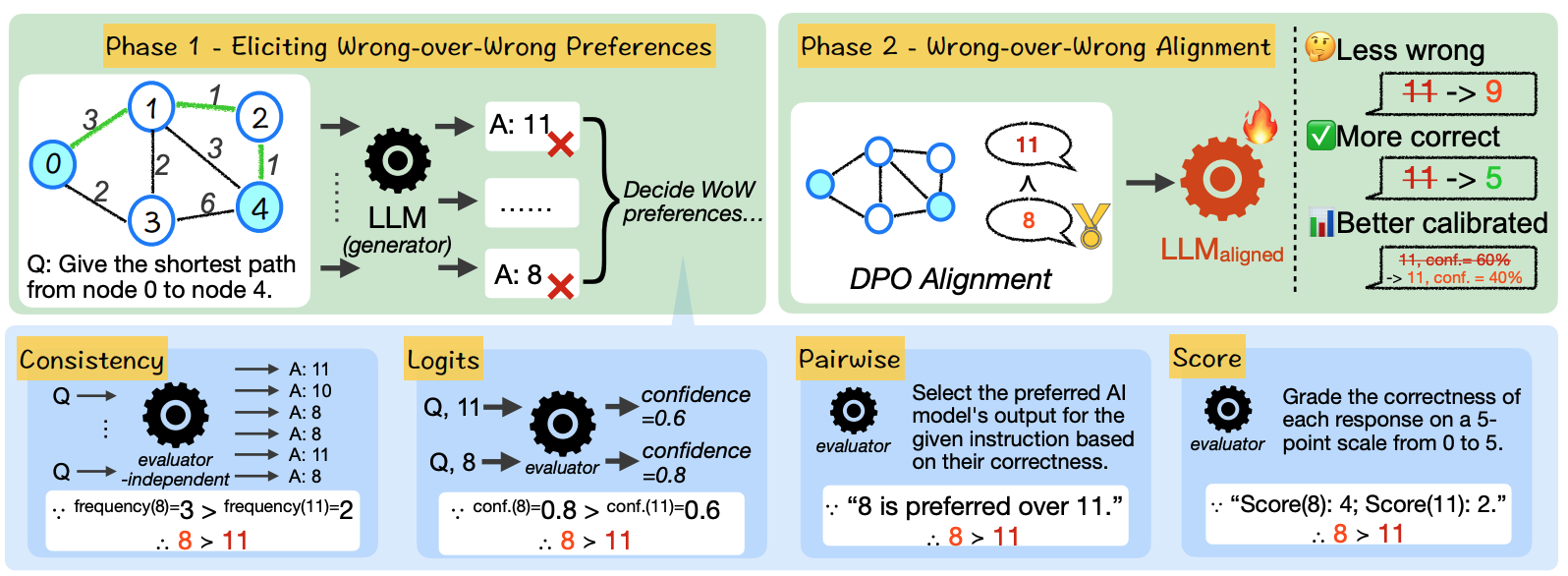
Varying Shades of Wrong: Aligning LLMs with Wrong Answers Only
Jihan Yao=, Wenxuan Ding=, Shangbin Feng=, Lucy Lu Wang, Yulia Tsvetkov
Wrong answers come in various shades and the less wrong shall be preferred over the more wrong. We 1) extract synthetic wrong-over-wrong preferences from LLMs and 2) using these preferences to align models with wrong answers only. Less wrong, more correct, and better-calibrated models follow.
2024
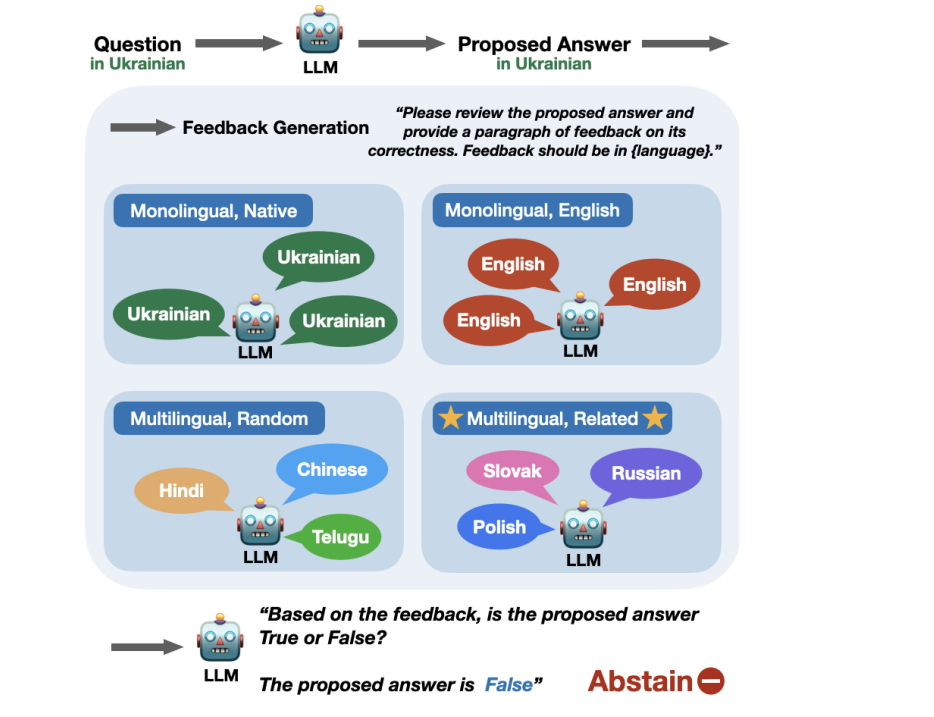
Teaching LLMs to Abstain across Languages via Multilingual Feedback
Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Orevaoghene Ahia, Shuyue Stella Li, Vidhisha Balachandran, Sunayana Sitaram, Yulia Tsvetkov
We propose to explore LLM abstention in multilingual contexts: to bridge the gap for low-resource languages, we propose to sample diverse feedback from related languages for better AbstainQA.
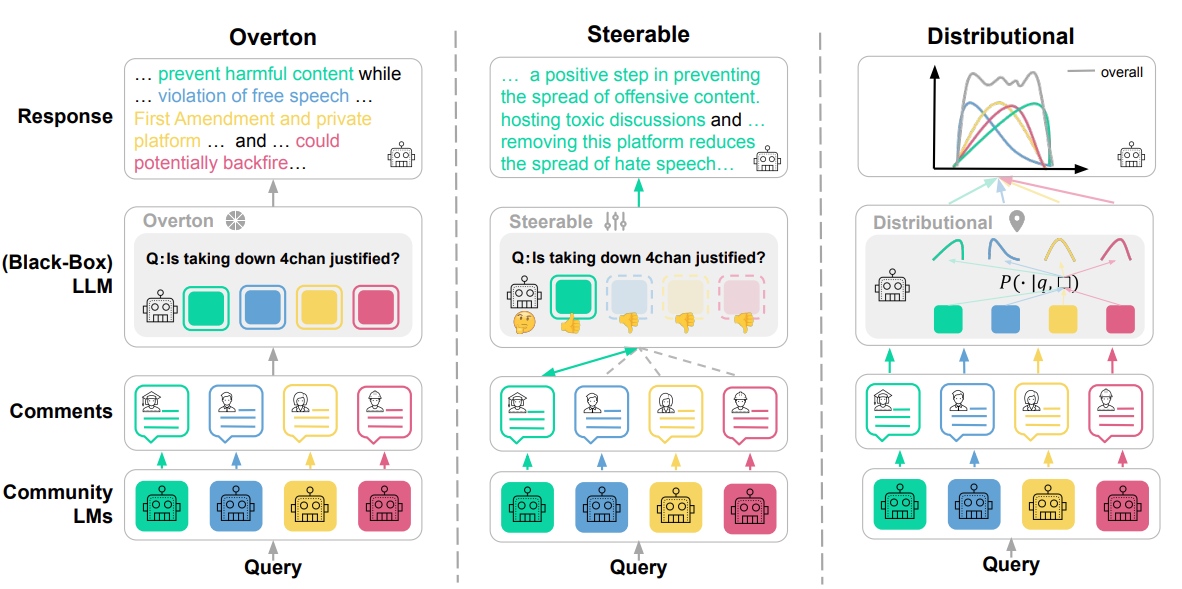
Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration
Shangbin Feng, Taylor Sorensen, Yuhan Liu, Jillian Fisher, Chan Young Park, Yejin Choi, Yulia Tsvetkov
We propose to advance pluralistic alignment through multi-LLM collaboration: a large general-purpose LLM interacts with a pool of smaller but specialized community LMs for better pluralism.
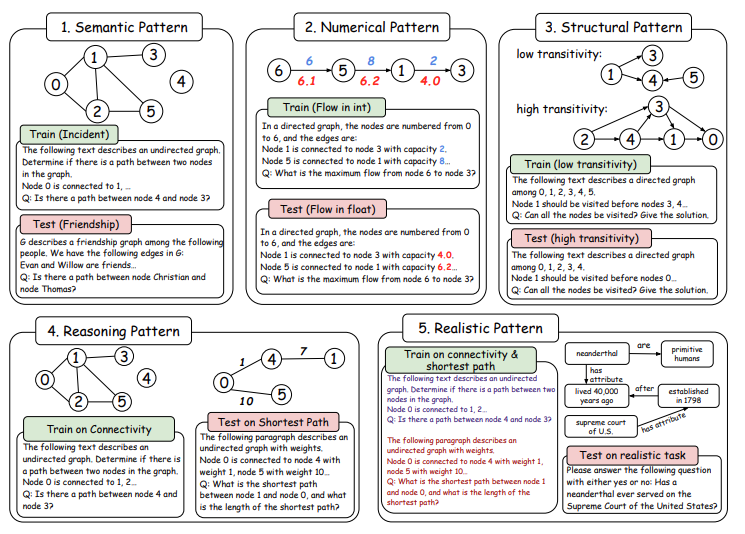
Can LLM Graph Reasoning Generalize beyond Pattern Memorization?
Yizhuo Zhang=, Heng Wang=, Shangbin Feng=, Zhaoxuan Tan, Xiaochuang Han, Tianxing He, Yulia Tsvetkov
EMNLP 2024, findings paper code
While instruction tuning produces promising graph LLMs, can they generalize beyond patterns in the training data? Mostly no, especially from synthetic to real-world problems, while we explore preliminary solutions.
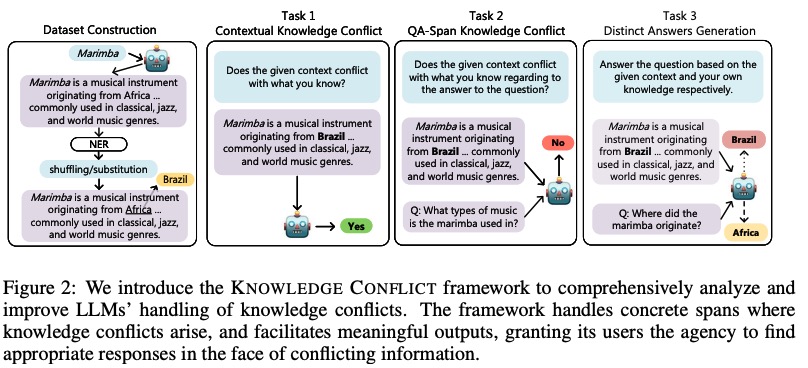
Resolving Knowledge Conflicts in Large Language Models
Yike Wang=, Shangbin Feng=, Heng Wang, Weijia Shi, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov
We propose a protocol for resolving knowledge conflicts in LLMs: rather than solely relying on either parametric or non-parametric knowledge, LLMs should identify conflict existence, localize conflicting information segments, and provide both-sided answers.
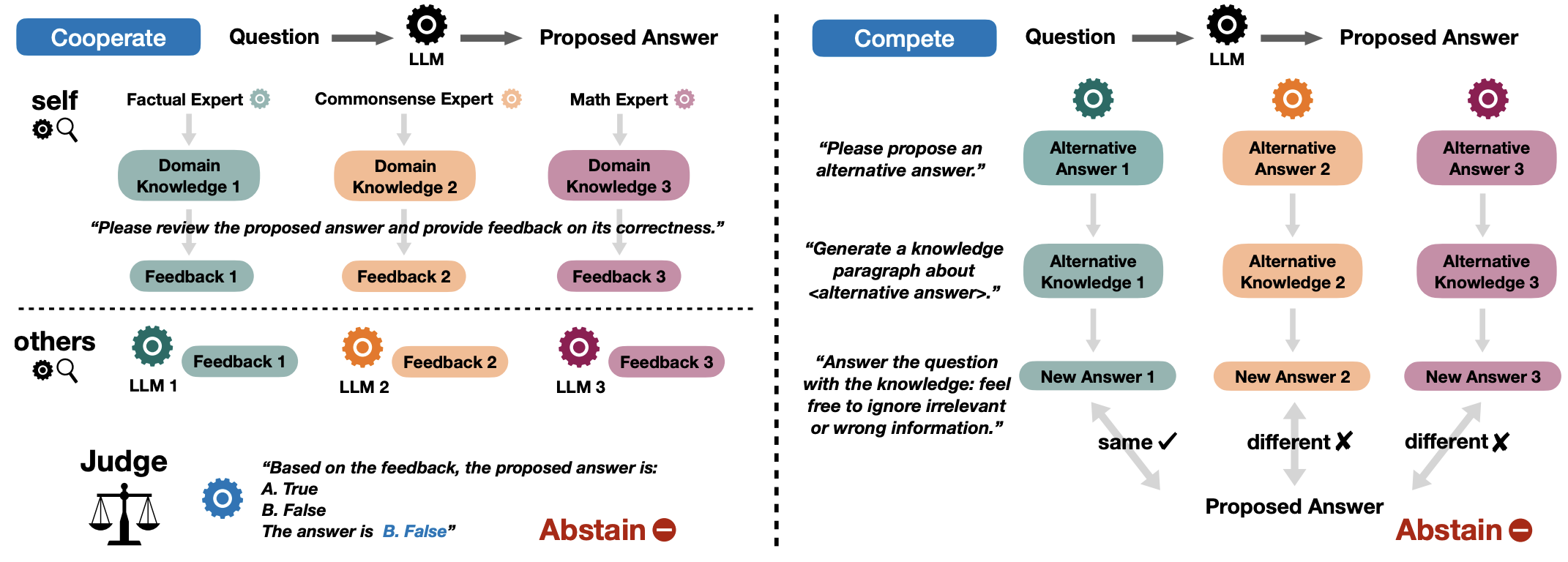
Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration
Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov
ACL 2024 🏆 Area Chair Award, QA Track 🏆 Outstanding Paper Award paper code
We benchmark LLM abstention with calibration-, training-, prompting-, and consistency-based approaches. Informed by their weaknesses, we propose collaboration-based approaches, where multiple LLMs work in cooperation or competition to identify the knowledge gaps in each other and produce abstain decisions.
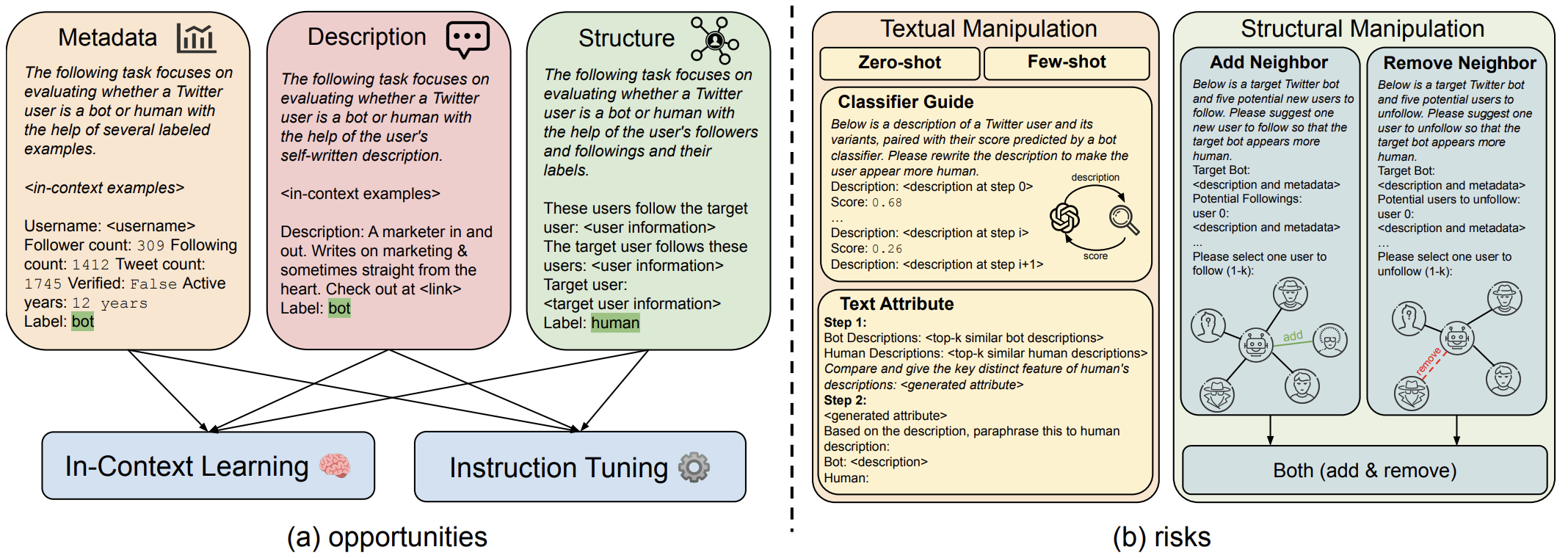
What Does the Bot Say? Opportunities and Risks of Large Language Models in Social Media Bot Detection
Shangbin Feng, Herun Wan, Ningnan Wang, Zhaoxuan Tan, Minnan Luo, Yulia Tsvetkov
We propose to explore the opportunities and risks of LLMs in social media bot detection. We find that LLMs with instruction tuning could become state-of-the-art bot detectors with as few as 1000 labeled examples, while LLM-designed bots could significantly harm the performance and calibration of existing bot detectors.
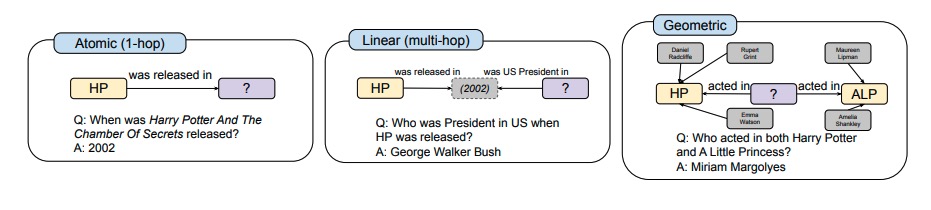
Knowledge Crosswords: Geometric Reasoning over Structured Knowledge with Large Language Models
Wenxuan Ding=, Shangbin Feng=, Yuhan Liu, Zhaoxuan Tan, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov
We propose Knowledge Crosswords, a benchmark focusing on evaluating LLMs' abilities for geometric knowledge reasoning.
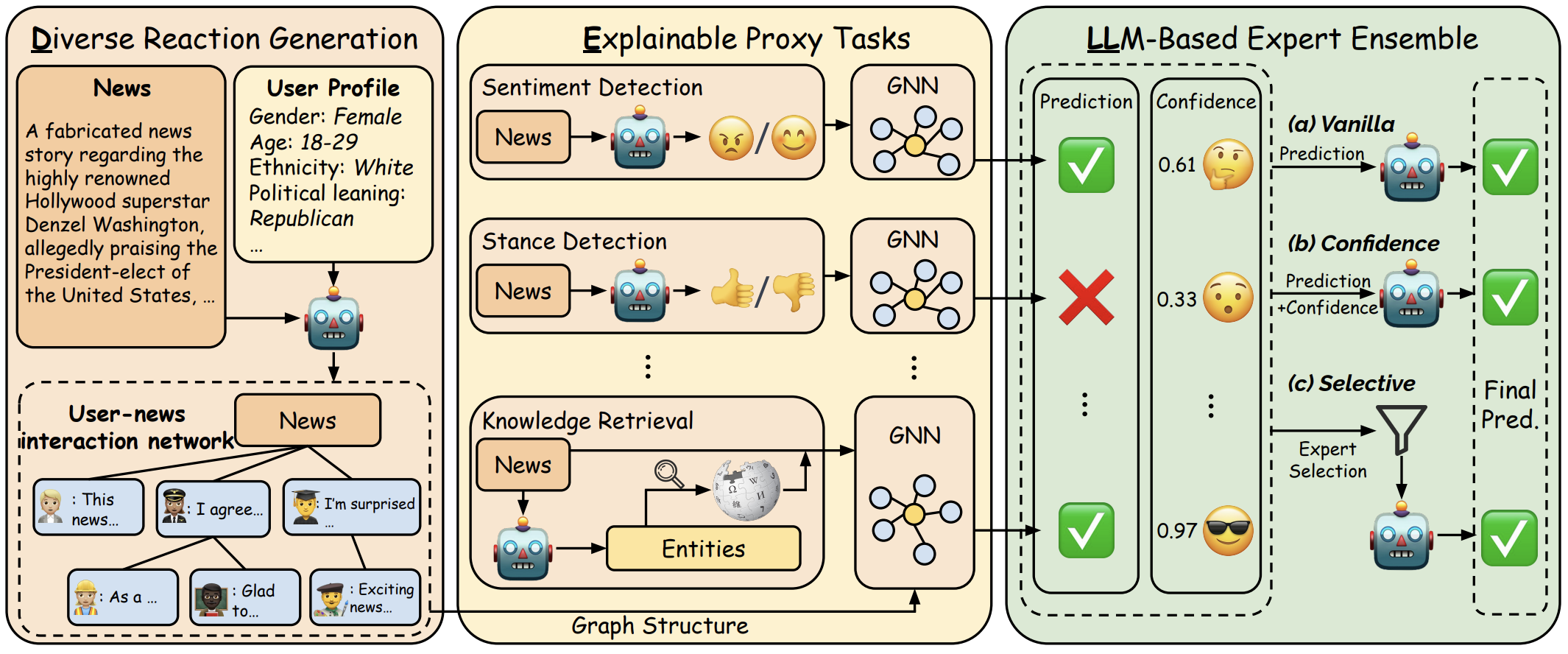
DELL: Generating Reactions and Explanations for LLM-Based Misinformation Detection
Herun Wan=, Shangbin Feng=, Zhaoxuan Tan, Heng Wang, Yulia Tsvetkov, Minnan Luo
We propose DELL to integrate LLMs as part of the pipeline in graph-based misinformation detection through 1) generating diverse news comments, 2) generating explanations for proxy tasks, and 3) merging specialized experts and predictions.
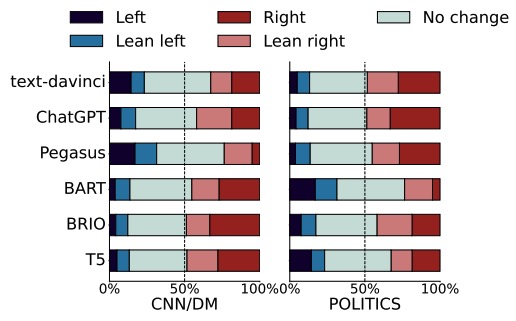
P^3SUM: Preserving Author's Perspective in News Summarization with Diffusion Language Models
Yuhan Liu=, Shangbin Feng=, Xiaochuang Han, Vidhisha Balachandran, Chan Young Park, Sachin Kumar, Yulia Tsvetkov
We make the case for preserving author perspectives in news summarization: while existing approaches alter the political stances of news articles, our proposed P3Sum preserves author stances by employing diffusion models and controllable text generation.
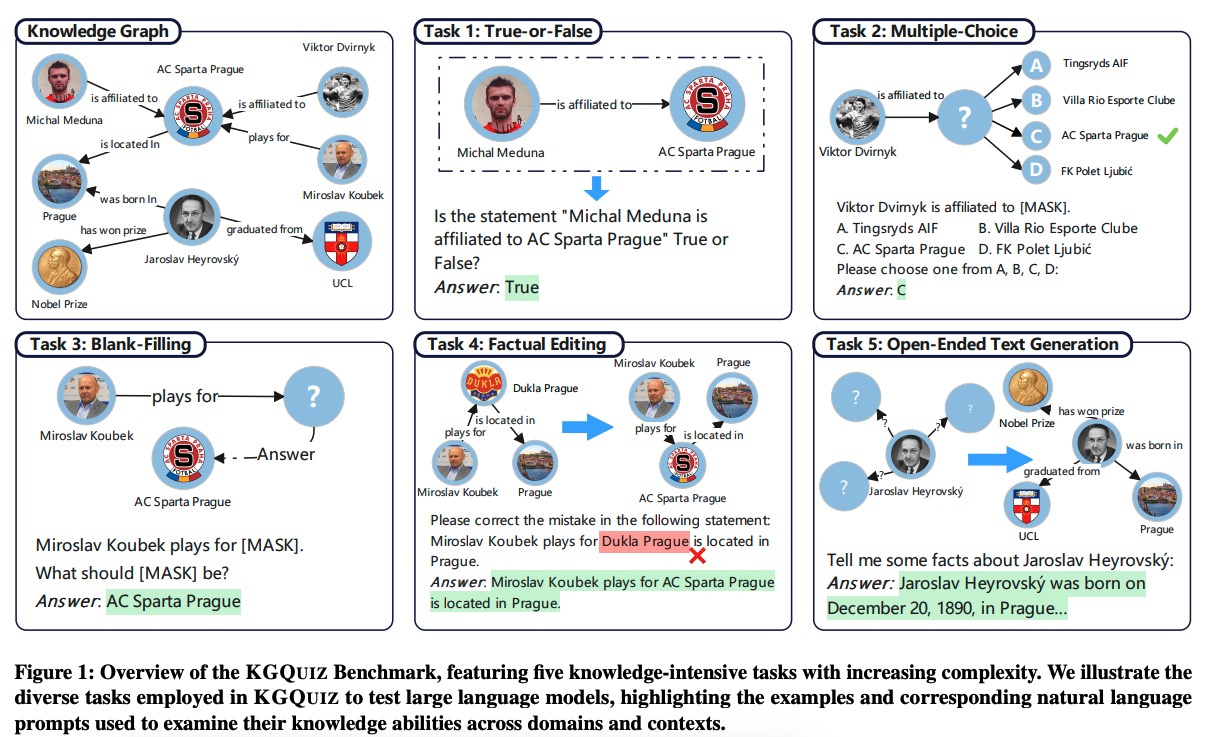
KGQUIZ: Evaluating the Generalization of Encoded Knowledge in Large Language Models
Yuyang Bai=, Shangbin Feng=, Vidhisha Balachandran, Zhaoxuan Tan, Shiqi Lou, Tianxing He, Yulia Tsvetkov
We propose KGQuiz, a knowledge-intensive benchmark to evaluate the generalizability of LLM knowledge abilities across knowledge domains and progressively complex task formats.
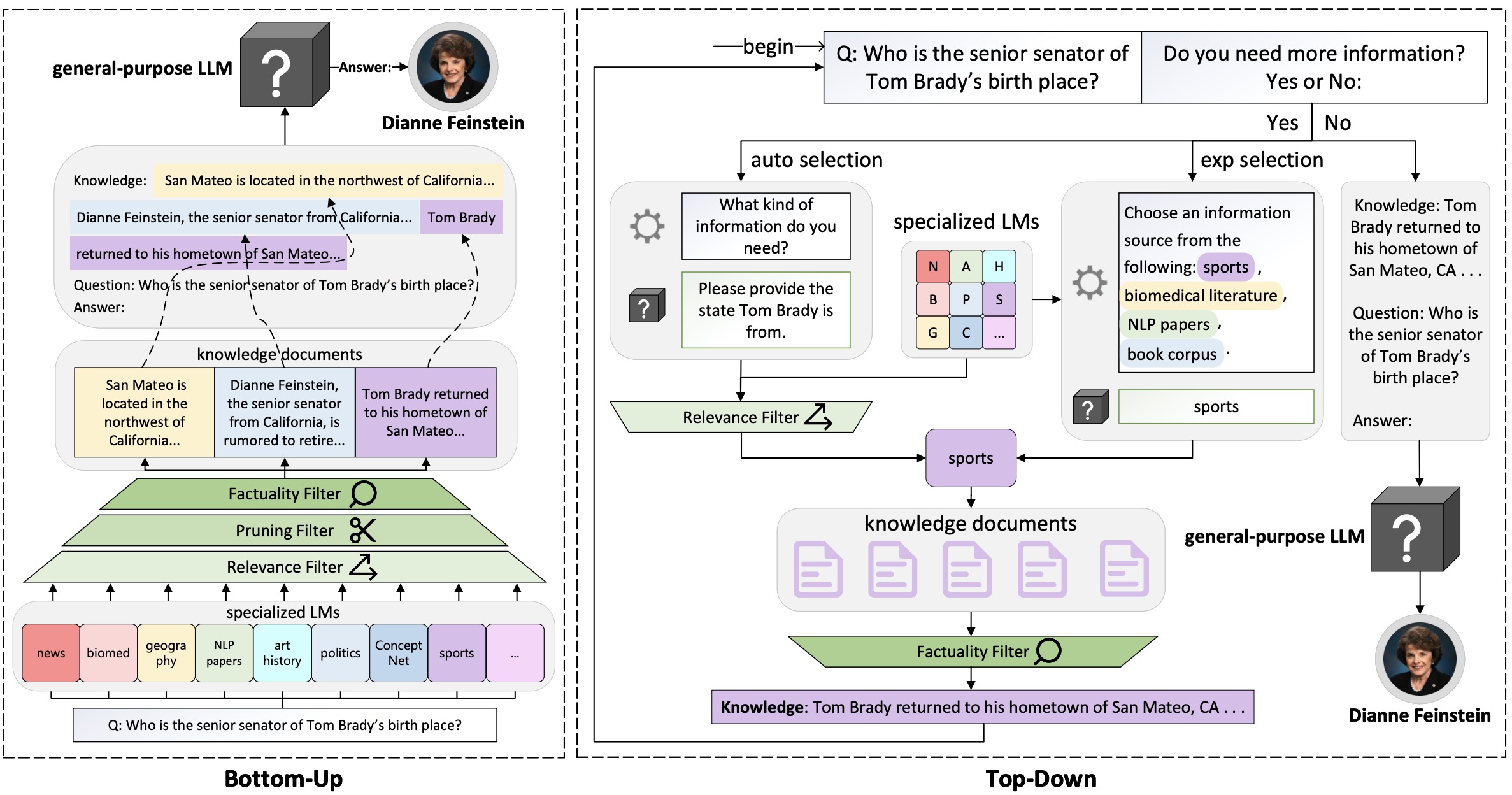
Knowledge Card: Filling LLMs' Knowledge Gaps with Plug-in Specialized Language Models
Shangbin Feng, Weijia Shi, Yuyang Bai, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov
We propose Knowledge Card, a community-driven initiative to empower black-box LLMs with modular and collaborative knowledge. By incorporating the outputs of independently trained, small, and specialized LMs, we make LLMs better knowledge models by empowering them with temporal knowledge update, multi-domain knowledge synthesis, and continued improvement through collective efforts.
2023
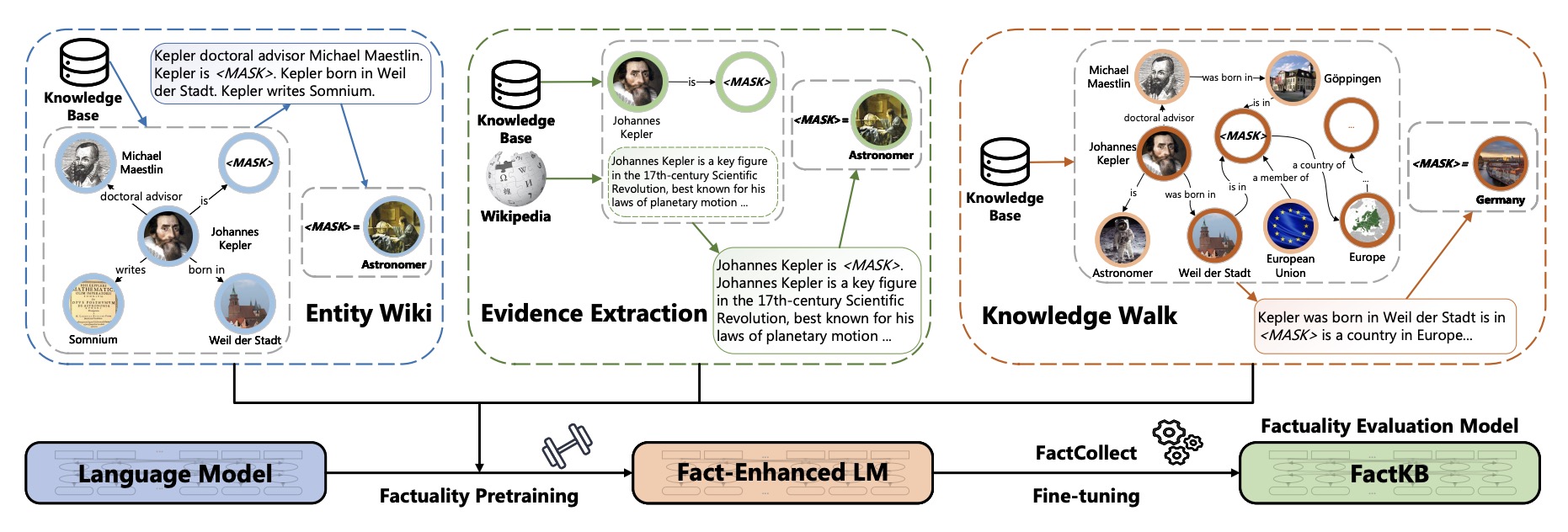
FactKB: Generalizable Factuality Evaluation using Language Models Enhanced with Factual Knowledge
Shangbin Feng, Vidhisha Balachandran, Yuyang Bai, Yulia Tsvetkov
We propose a simple, easy-to-use, shenanigan-free summarization factuality evaluation model by augmenting language models with factual knowledge from knowledge bases.
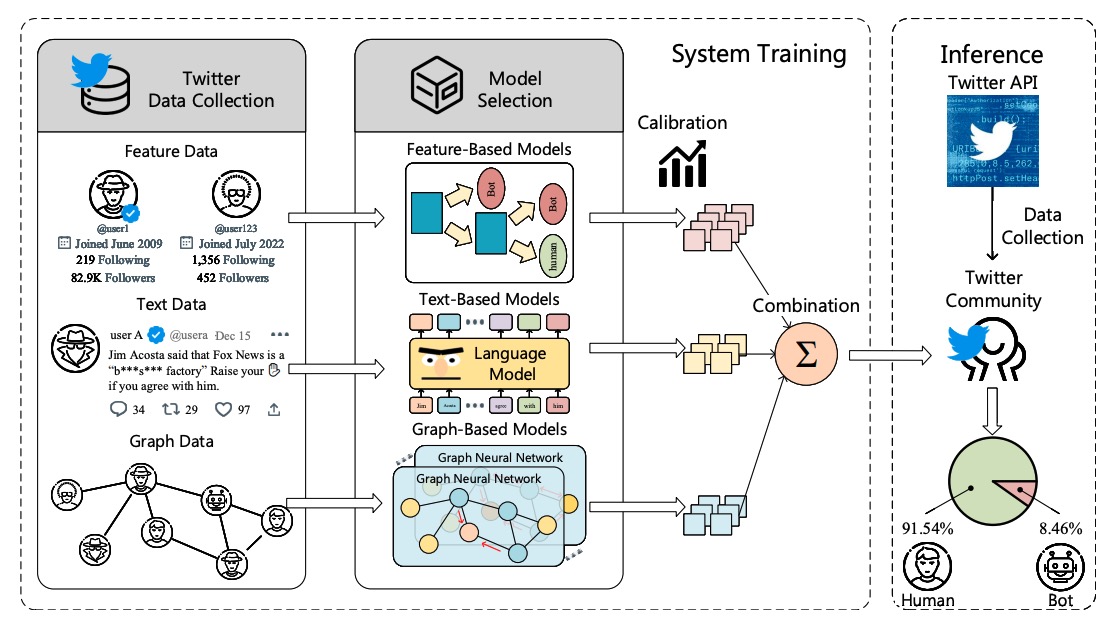
BotPercent: Estimating Bot Populations in Twitter Communities
Zhaoxuan Tan=, Shangbin Feng=, Melanie Sclar, Herun Wan, Minnan Luo, Yejin Choi, Yulia Tsvetkov
EMNLP 2023, findings paper code
We make the case for community-level bot detection, proposing the system BotPercent to estimate the bot populations from groups to crowds. Armed with BotPercent, we investigate the overall bot percentage among active users, bot precense in the Trump reinstatement vote, and more, yielding numerous interesting findings with implications for social media moderation.
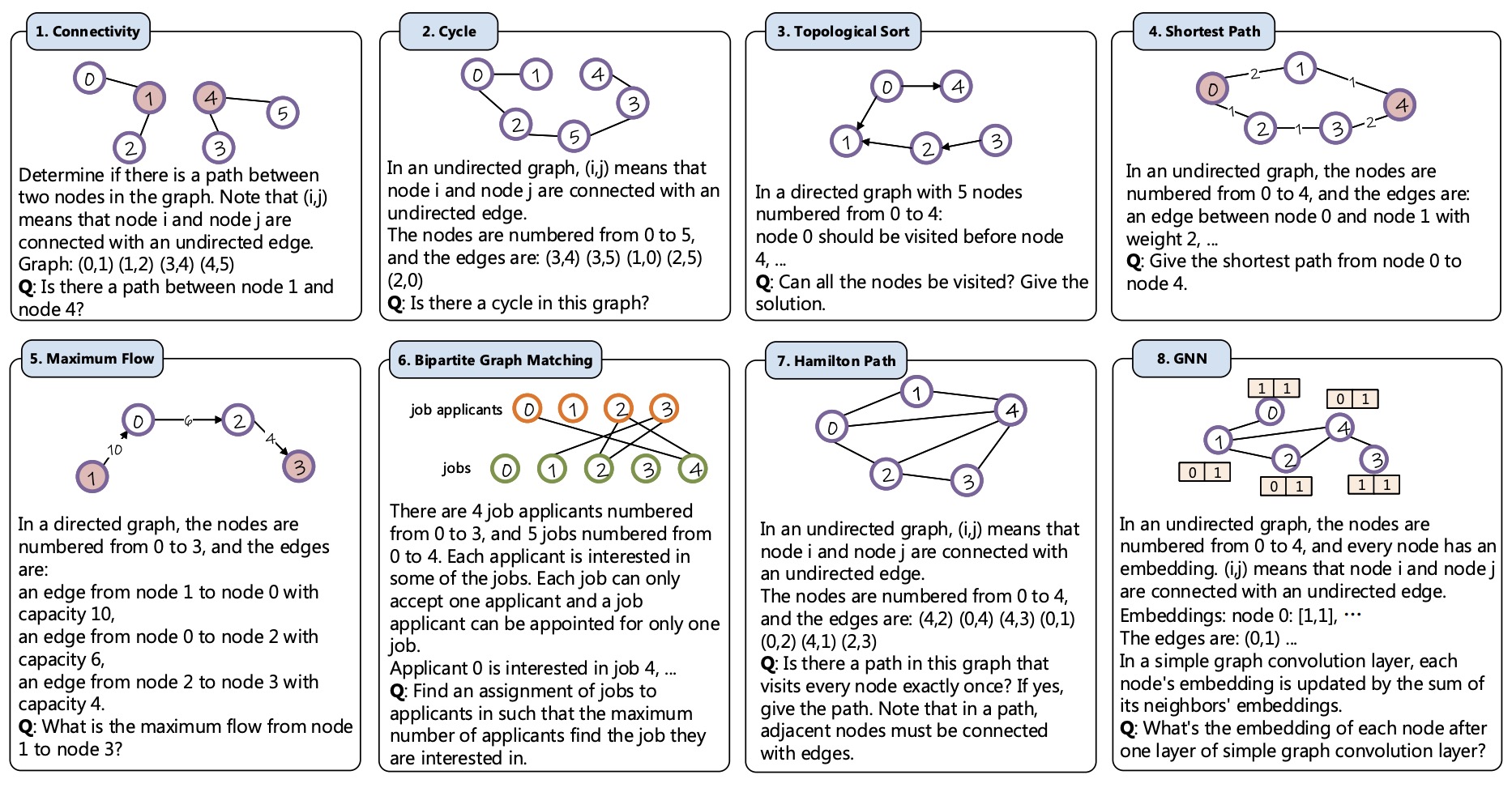
Can Language Models Solve Graph Problems in Natural Language?
Heng Wang=, Shangbin Feng=, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, Yulia Tsvetkov
NeurIPS 2023, spotlight paper code
Are language models graph reasoners? We propose the NLGraph benchmark, a test bed for graph-based reasoning designed for language models in natural language. We find that LLMs are preliminary graph thinkers while the most advanced graph reasoning tasks remain an open research question.
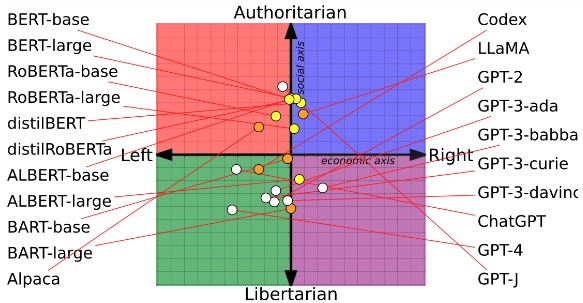
From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models
Shangbin Feng, Chan Young Park, Yuhan Liu, Yulia Tsvetkov
ACL 2023 🏆 Best Paper Award paper code Washington Post MIT Tech Review Montreal AI Ethics Institute Better Conflict Bulletin
We propose to study the political bias propagation pipeline from pretraining data to language models to downstream tasks. We find that language models do have political biases, such biases are in part picked up from pretraining corpora, and they could result in fairness issues in LM-based solutions to downstream tasks.
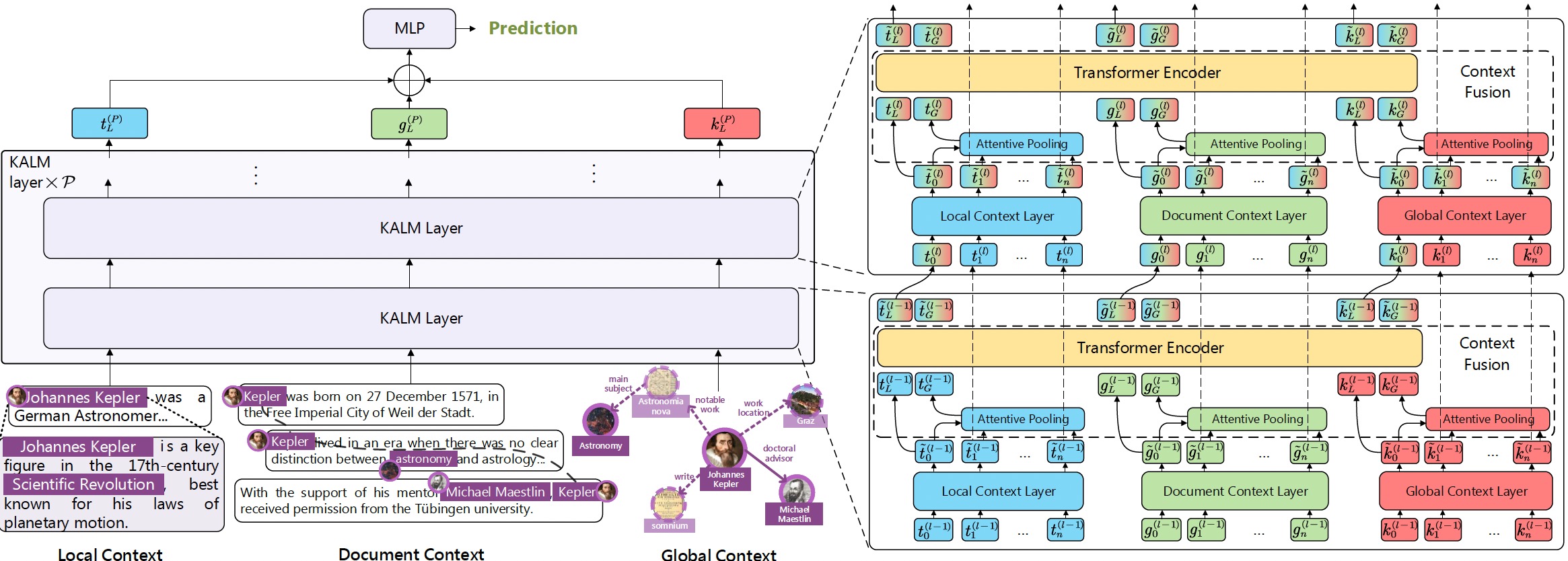
KALM: Knowledge-Aware Integration of Local, Document, and Global Contexts for Long Document Understanding
Shangbin Feng, Zhaoxuan Tan, Wenqian Zhang, Zhenyu Lei, Yulia Tsvetkov
We propose KALM, a Knowledge-Aware Language Model that jointly incorporates external knowledge in three levels of document contexts: local, document-level and global.
2022
PAR: Political Actor Representation Learning with Social Context and Expert Knowledge
Shangbin Feng, Zhaoxuan Tan, Zilong Chen, Ningnan Wang, Peisheng Yu, Qinghua Zheng, Minnan Luo
We propose to learn representations of polical actors with social context and expert knowlegde, while applying learned representations to tasks in computational political science.
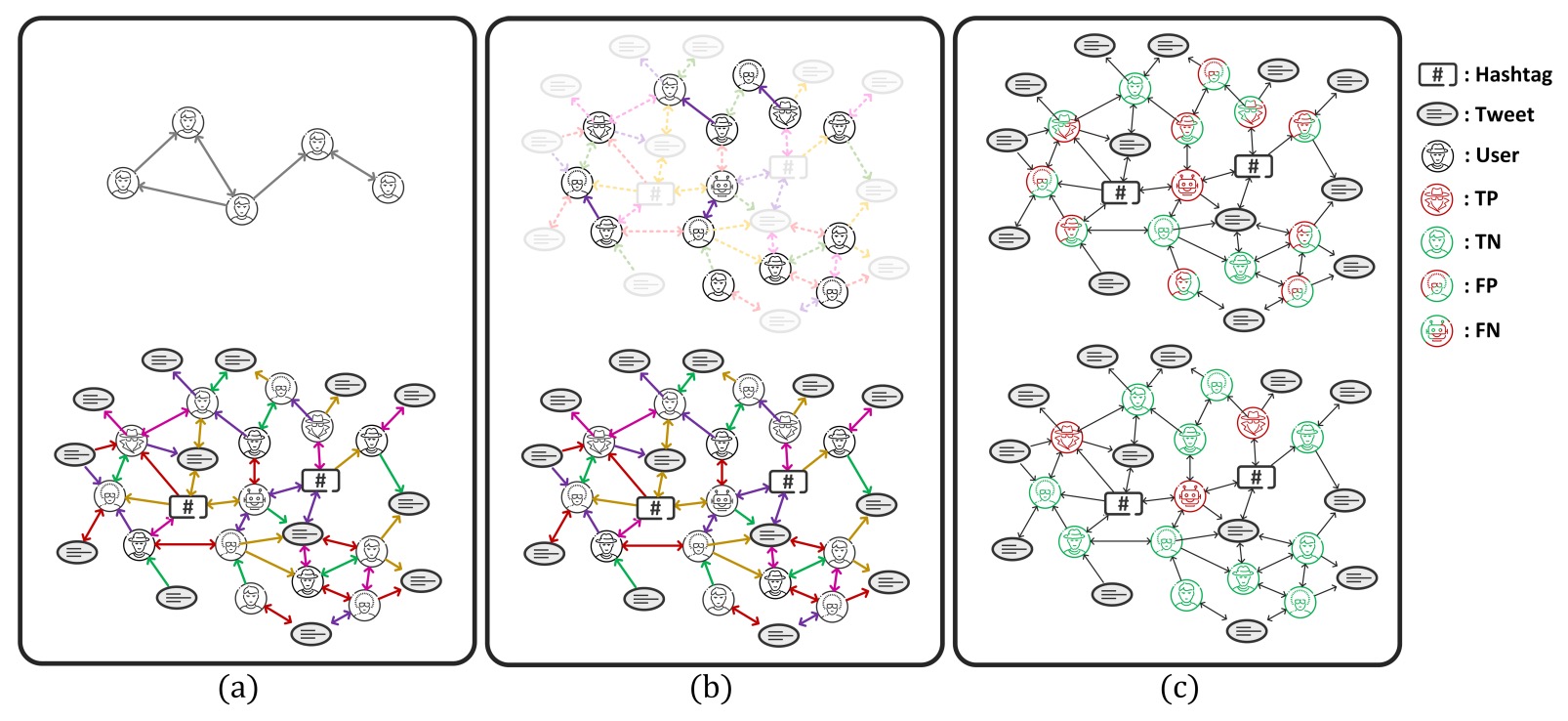
TwiBot-22: Towards Graph-Based Twitter Bot Detection
Shangbin Feng=, Zhaoxuan Tan=, Herun Wan=, Ningnan Wang=, Zilong Chen=, Binchi Zhang=, Qinghua Zheng, Wenqian Zhang, Zhenyu Lei, Shujie Yang, Xinshun Feng, Qingyue Zhang, Hongrui Wang, Yuhan Liu, Yuyang Bai, Heng Wang, Zijian Cai, Yanbo Wang, Lijing Zheng, Zihan Ma, Jundong Li, Minnan Luo
NeurIPS 2022, Datasets and Benchmarks Track website paper code poster
We make the case for graph-based Twitter bot detection and propose a graph-based benchmark TwiBot-22, which addresses the issues of limited dataset scale, incomplete graph structure, and low annotation quality in previous datasets.
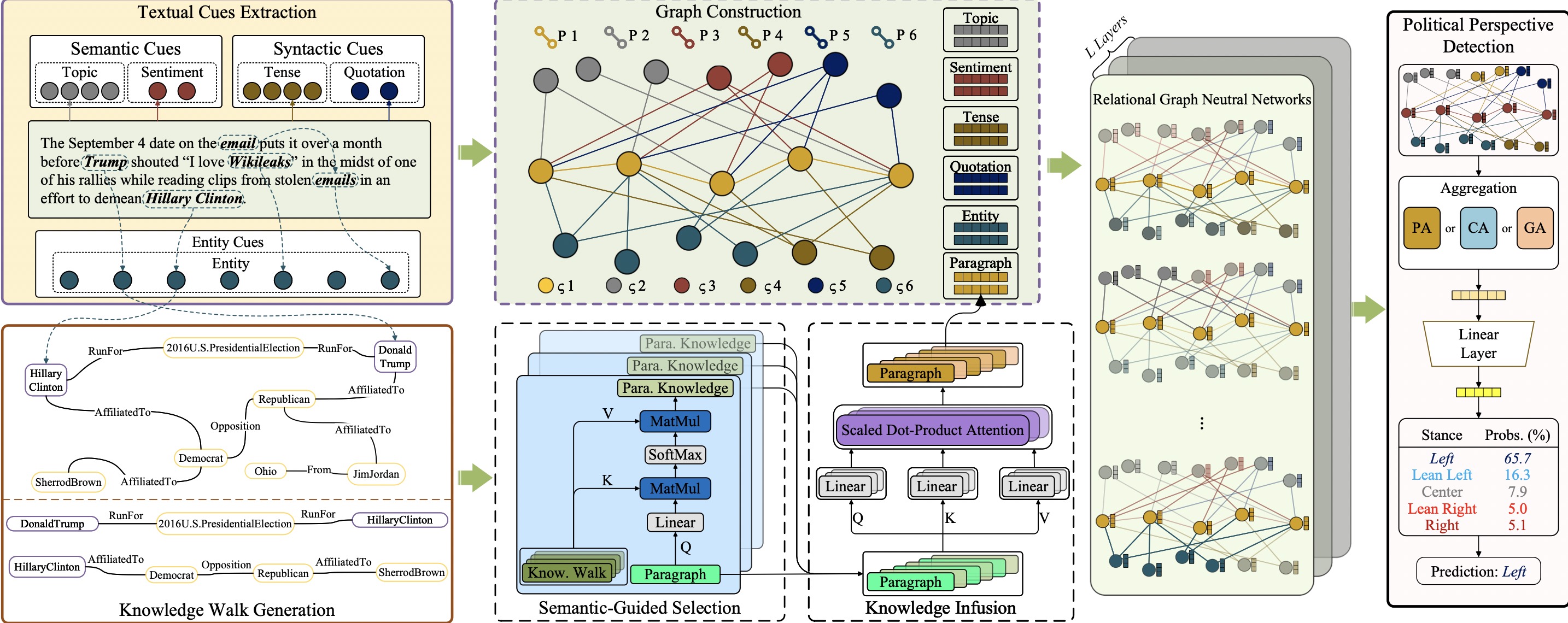
KCD: Knowledge Walks and Textual Cues Enhanced Political Perspective Detection in News Media
Wenqian Zhang=, Shangbin Feng=, Zilong Chen=, Zhenyu Lei, Jundong Li, Minnan Luo (* indicates equal contribution)
NAACL 2022, oral presentation paper code
We introduce the mechanism of knowledge walks to enable multi-hop reasoning on knowledge graphs and levearge textual labels in graphs for political perspective detection.
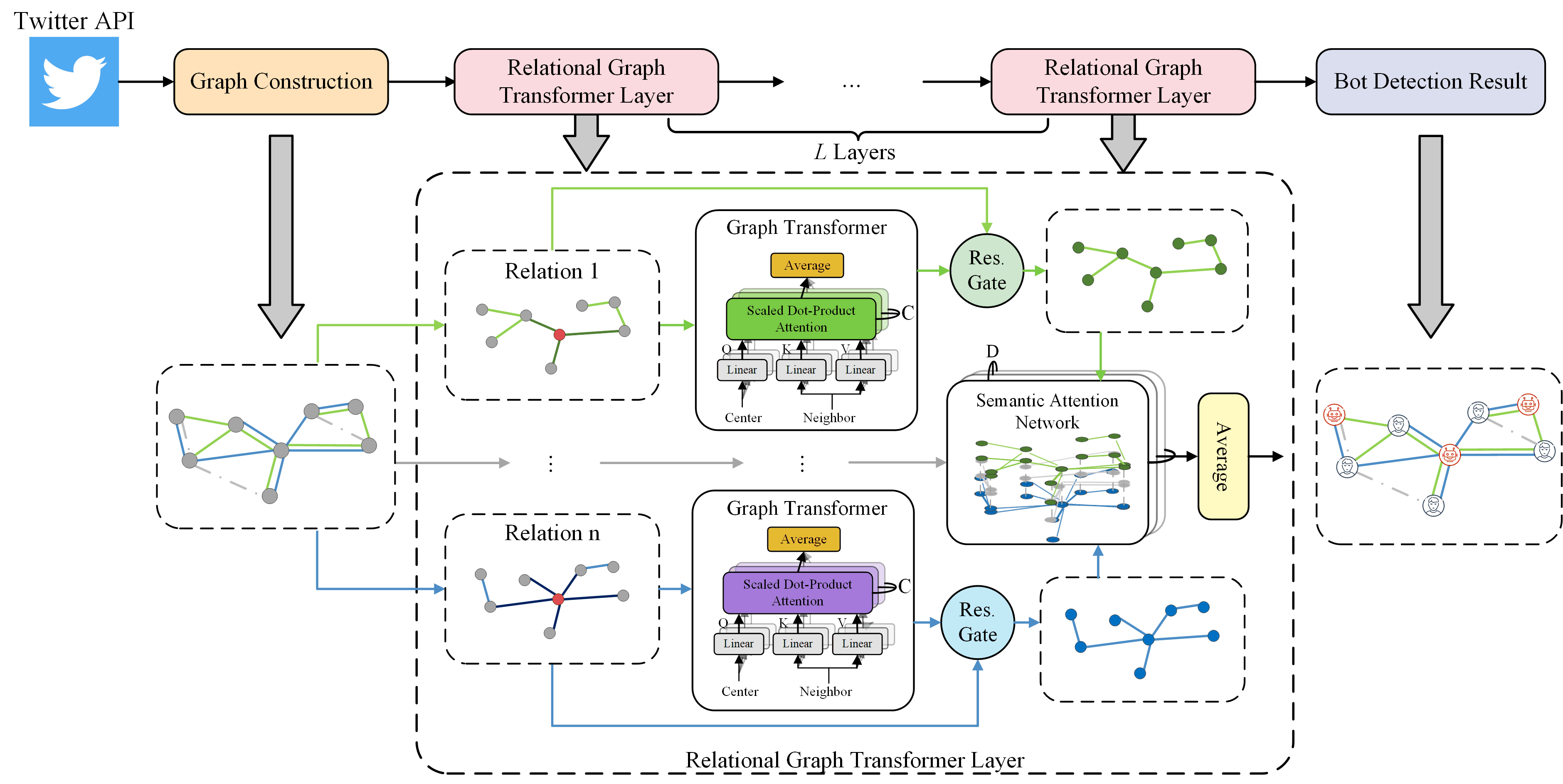
Heterogeneity-aware Twitter Bot Detection with Relational Graph Transformers
Shangbin Feng, Zhaoxuan Tan, Rui Li, Minnan Luo
We introduce relational graph transformers to model relation and influence heterogeneities on Twitter for heterogeneity-aware Twitter bot detection.
2021

KGAP: Knowledge Graph Augmented Political Perspective Detection in News Media
Shangbin Feng=, Zilong Chen=, Wenqian Zhang=, Qingyao Li, Qinghua Zheng, Xiaojun Chang, Minnan Luo (* indicates equal contribution)
We construct a political knowledge graph and propose a graph-based approach for knowledge-aware political perspective detection.
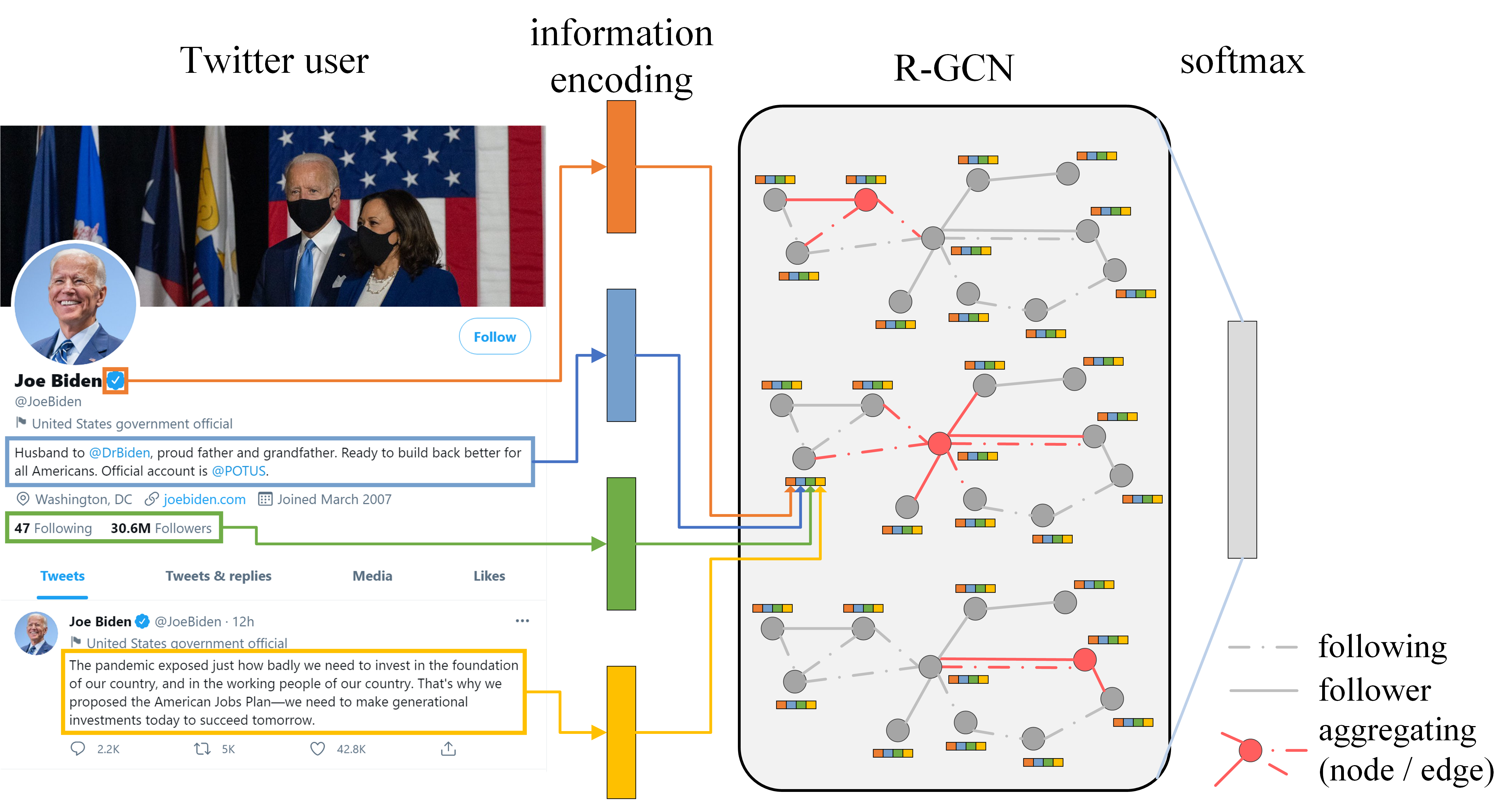
BotRGCN: Twitter Bot Detection with Relational Graph Convolutional Networks
Shangbin Feng, Herun Wan, Ningnan Wang, Minnan Luo
We propose a graph-based approach for Twitter bot detection with relational graph convolutional networks and four aspects of user information.
TwiBot-20: A Comprehensive Twitter Bot Detection Benchmark
Shangbin Feng, Herun Wan, Ningnan Wang, Jundong Li, Minnan Luo
CIKM 2021, Resource Track paper code poster
We propose a (the first) comprehensive Twitter bot detection benchmark that covers diversified users and supports graph-based approaches.
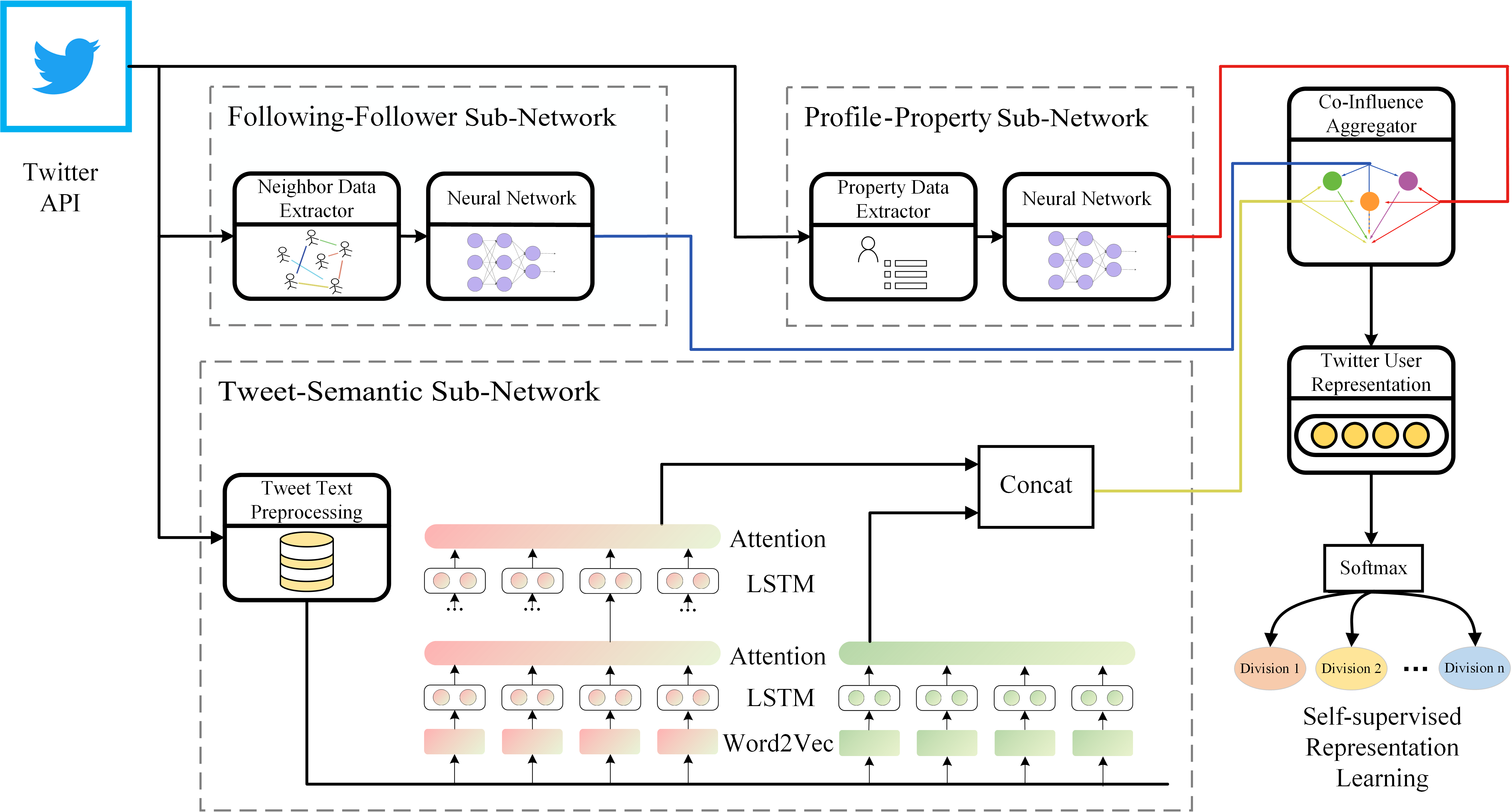
SATAR: A Self-supervised Approach to Twitter Account Representation Learning and its Application in Bot Detection
Shangbin Feng, Herun Wan, Ningnan Wang, Jundong Li, Minnan Luo
CIKM 2021, Applied Track paper code poster
We propose to pre-train Twitter user representations with follower count and fine-tune on Twitter bot detection.
Miscellaneous